Loading Data via Pipelines
A pipeline in Databend Cloud allows for automatic discovery of file updates from Amazon S3 and automatically loads them into a table. Here are some scenarios where using a pipeline is recommended:
You have a large number of CSV or Parquet files in an S3 bucket and want to load them to Databend Cloud in one go for further analysis.
AWS automatically loads data into your S3 buckets, such as billing data, which can be automatically loaded into Databend Cloud for visualization and further analysis.
You have a continuous stream of user behavior logs being stored in S3, which can be automatically loaded into Databend Cloud using pipelines for further analysis.
During public beta, pipeline is offered free of charge on Databend Cloud. Limit of 4 Pipelines per organization. Contact us by submitting a ticket for additional requests.
Creating a Pipeline
To create a pipeline in Databend Cloud, you must first create a table that will serve as the target for the data to be imported into. The table schema must match the structure of the data to be imported in order for the pipeline to work properly.
To create a pipeline:
- On the Data page, navigate to and select your target table, then select the Pipeline tab on the right.
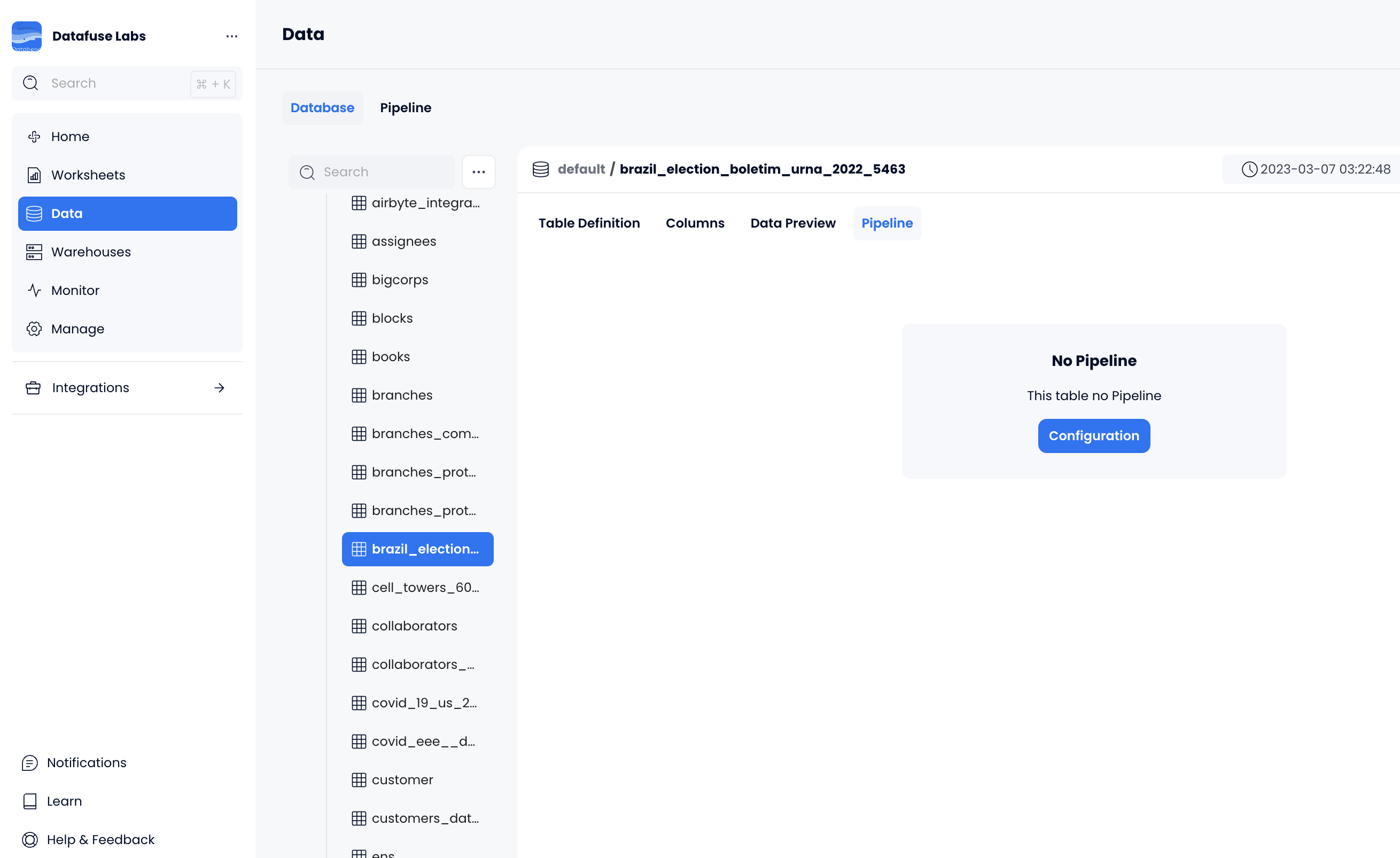
Click Configuration to create a pipeline, then provide the required information to enable access to your files in an Amazon S3 bucket.
If you import CSV files, you can specify details about the file format by clicking Settings.
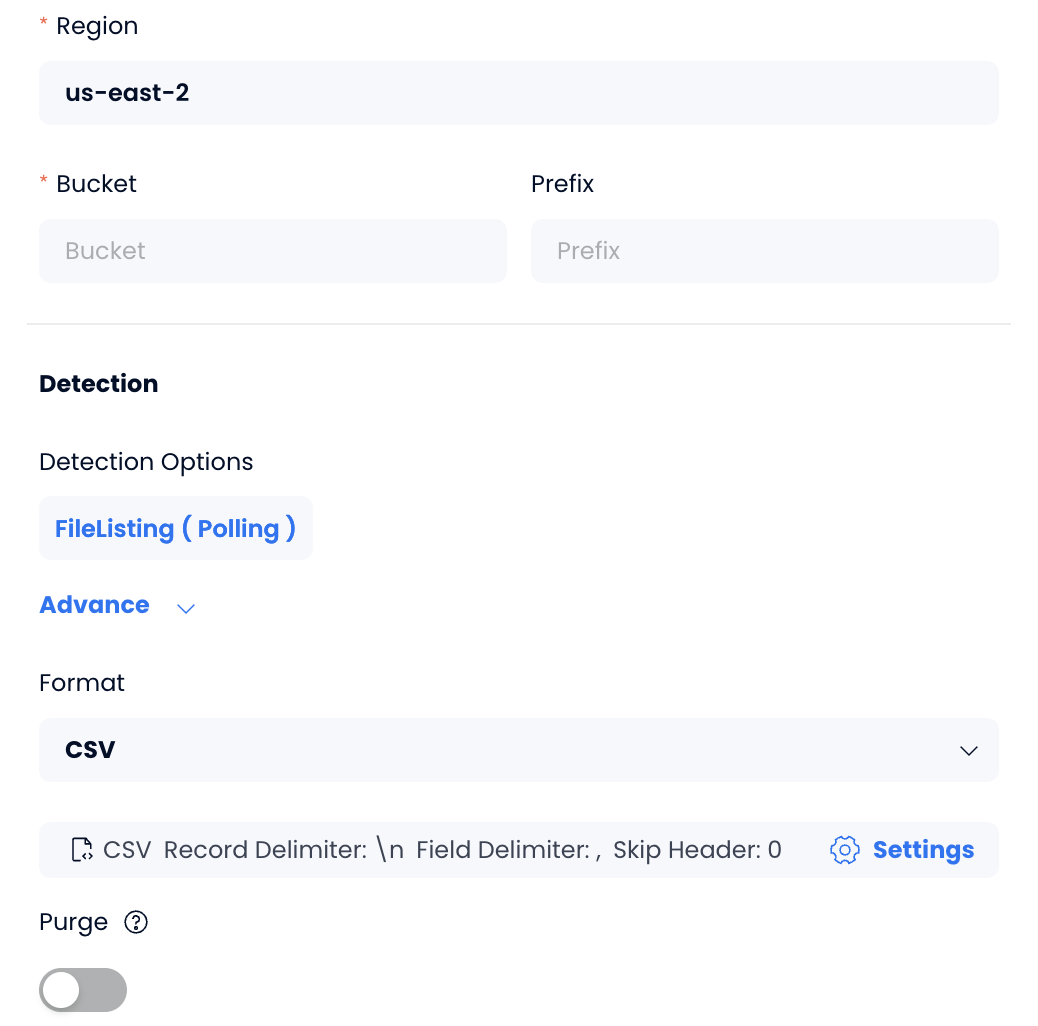
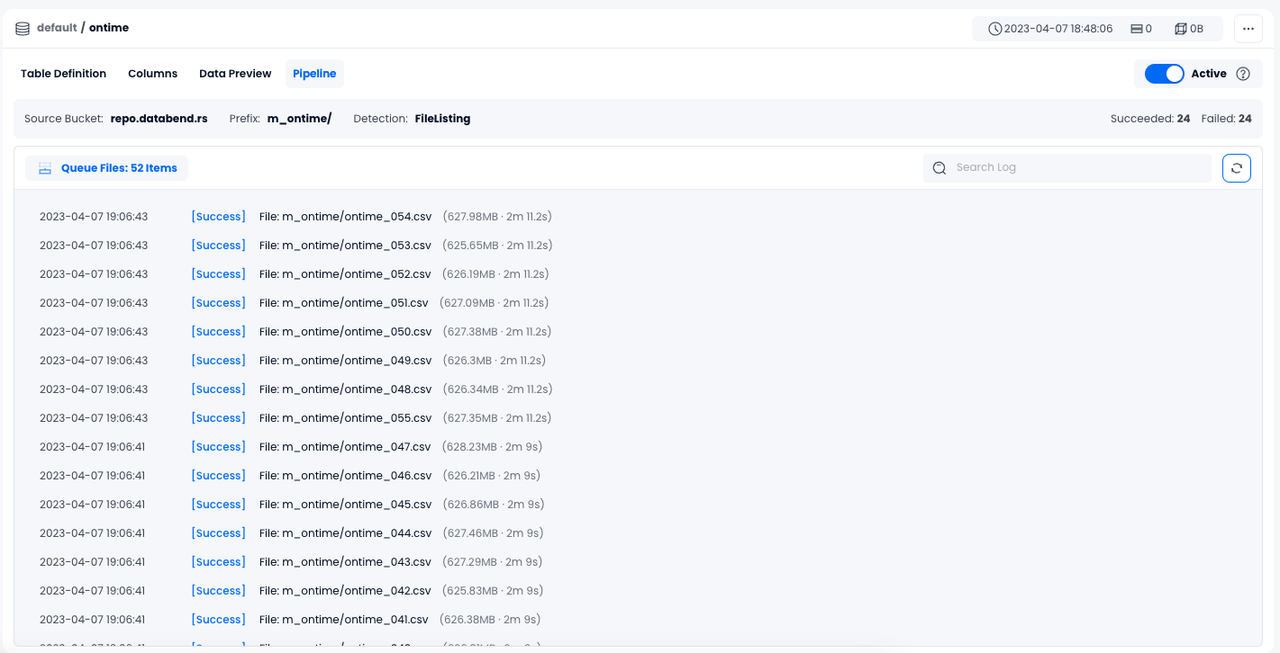
- Click OK. The data loading process will begin only if all the connection information is accurate. After the loading is complete, you will be able to view the import logs like this on the page:
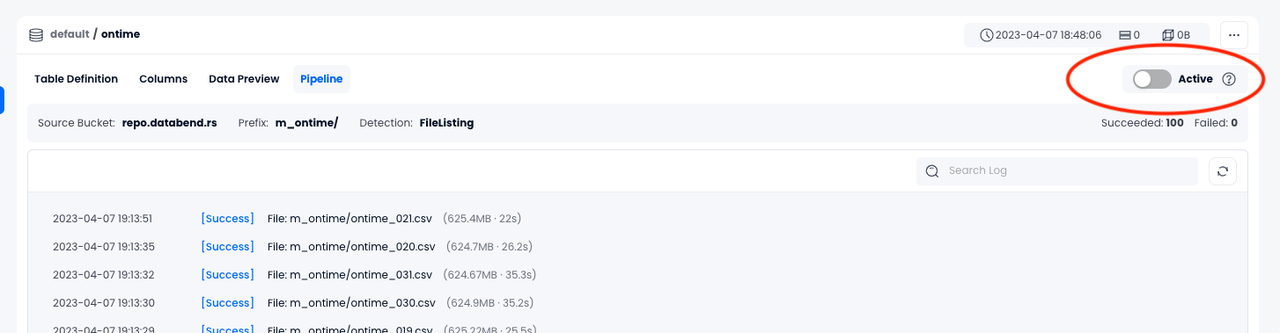
Activating or Deactivating a Pipeline
Once created successfully, a pipeline is activated by default. The pipeline will periodically detect your file changes on Amazon S3 and automatically load them into the table in Databend Cloud until you deactivate it.
To deactivate a pipeline, go to the Pipeline tab and toggle the Active button.