淘宝用户行为分析
在本案例中,我们将使用 Databend Cloud 对来自天池实验室的淘宝用户购物行为数据集进行分析,一起发现有趣的购物行为。
该数据集为 CSV 格式,包含了 2017 年 11 月 25 日至 2017 年 12 月 3 日之间,有行为的约一百万随机用户的所有行为(包括点击、购买、加购、喜欢)。数据集的每一行表示一条用户行为,由以下 5 列组成,并以逗号分隔:
| 列名称 | 说明 |
|---|---|
| 用户 ID | 整数类型,序列化后的用户 ID |
| 商品 ID | 整数类型,序列化后的商品 ID |
| 商品类目 ID | 整数类型,序列化后的商品所属类目 ID |
| 行为类型 | 字符串,枚举类型,包括:'pv':商品详情页 pv,等价于点击; 'buy':商品购买; 'cart':将商品加入购物车; 'fav':收藏商品 |
| 时间戳 | 行为发生的时间戳 |
准备工作
1
下载数据集
- 下载淘宝用户购物行为数据集到本地,然后使用以下命令解压:
unzip UserBehavior.csv.zip
- 将解压后的数据集文件 (UserBehavior.csv) 压缩为 gzip 格式:
gzip UserBehavior.csv
2
创建外部 Stage
-
登入 Databend Cloud,并新建一个工作区。
-
在工作区中,执行以下 SQL 语句在阿里云上创建一个名为"mycsv"的外部 Stage:
CREATE STAGE mycsv URL = 's3://<YOUR_BUCKET_NAME>'
CONNECTION = (
ACCESS_KEY_ID = '<YOUR_ACCESS_KEY_ID>',
SECRET_ACCESS_KEY = '<YOUR_SECRET_ACCESS_KEY>',
ENDPOINT_URL = '<YOUR_ENDPOINT_URL>',
ENABLE_VIRTUAL_HOST_STYLE = TRUE
)
FILE_FORMAT = (
TYPE = CSV
COMPRESSION = AUTO
);
- 执行以下 SQL 语句验证 Databend Cloud 是否可访问到该外部 Stage:
LIST @mycsv;
3
上传数据集到外部 Stage
使用 BendSQL将压缩后的数据集文件 (UserBehavior.csv.gz) 上传到外部 Stage。获取计算集群的连接信息,请参考连接到计算集群。
(base) eric@Erics-iMac ~ % bendsql --host tenantID--YOUR_WAREHOUSE.gw.aliyun-cn-beijing.default.databend.cn \
--user=cloudapp \
--password=<YOUR_PASSWORD> \
--database="default" \
--port=443 --tls
Welcome to BendSQL 0.9.3-db6b232(2023-10-26T12:36:55.578667000Z).
Connecting to tenantID--YOUR_WAREHOUSE.gw.aliyun-cn-beijing.default.databend.cn:443 as user cloudapp.
Connected to DatabendQuery v1.2.183-nightly-1ed9a826ed(rust-1.72.0-nightly-2023-10-28T22:10:15.618365223Z)
cloudapp@tenantID--YOUR_WAREHOUSE.gw.aliyun-cn-beijing.default.databend.cn:443/default> PUT fs:///Users/eric/Documents/UserBehavior.csv.gz @mycsv
PUT fs:///Users/eric/Documents/UserBehavior.csv.gz @mycsv
┌─────────────────────────────────────────────────────────────────┐
│ file │ status │ size │
│ String │ String │ UInt64 │
├───────────────────────────────────────────┼─────────┼───────────┤
│ /Users/eric/Documents/UserBehavior.csv.gz │ SUCCESS │ 949805035 │
└─────────────────────────────────────────────────────────────────┘
1 file uploaded in 401.807 sec. Processed 1 file, 905.80 MiB (0.00 file/s, 2.25 MiB/s)
数据导入和清洗
1
创建表格
在工作区中,执行以下 SQL 语句为数据集创建表格:
CREATE TABLE `user_behavior` (
`user_id` INT NOT NULL,
`item_id` INT NOT NULL,
`category_id` INT NOT NULL,
`behavior_type` VARCHAR,
`ts` TIMESTAMP,
`day` DATE );
2
清洗、导入数据
-
执行以下 SQL 语句导入数据到表格中,并同时完成清洗:
- 去除无效的时间区外的数据
- 数据去重
- 生成额外列数据
INSERT INTO user_behavior
SELECT $1,$2,$3,$4,to_timestamp($5::bigint) AS ts, to_date(ts) day
FROM @mycsv/UserBehavior.csv.gz WHERE day BETWEEN '2017-11-25' AND '2017-12-03'
GROUP BY $1,$2,$3,$4,ts;
- 执行以下 SQL 语句验证数据导入是否成功。该语句将返回表格的 10 行数据。
SELECT * FROM user_behavior LIMIT 10;
数据分析
在完成了前期的准备和数据导入之后,我们正式开始进行数据分析。
用户流量及购物情况分析
1
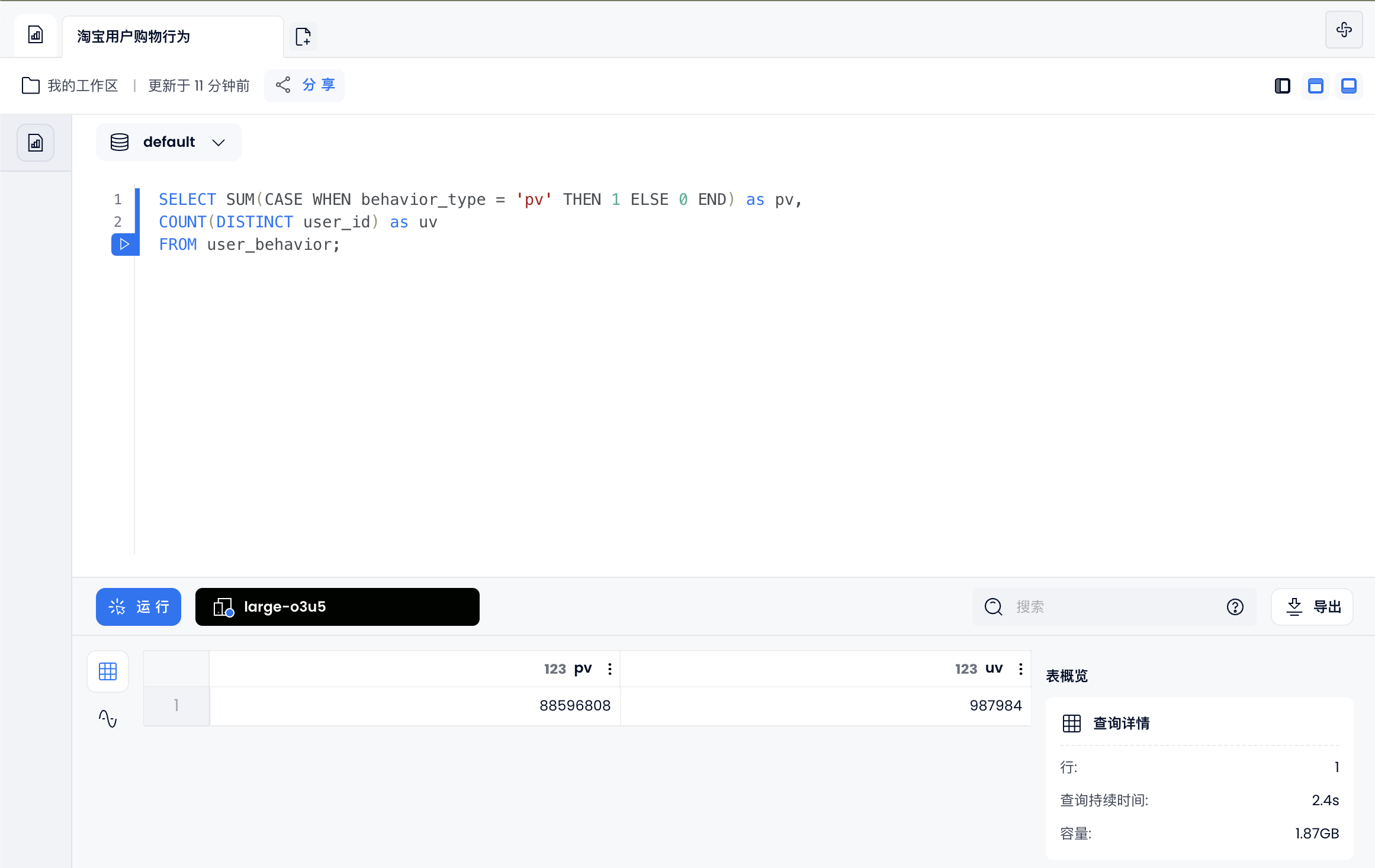
总访问量和用户数
SELECT SUM(CASE WHEN behavior_type = 'pv' THEN 1 ELSE 0 END) as pv,
COUNT(DISTINCT user_id) as uv
FROM user_behavior;
3
统计每个用户的购物情况,生成新表:user_behavior_count
create table user_behavior_count as select user_id,
sum(case when behavior_type = 'pv' then 1 else 0 end) as pv, --点击数
sum(case when behavior_type = 'fav' then 1 else 0 end) as fav, --收藏数
sum(case when behavior_type = 'cart' then 1 else 0 end) as cart, --加购物车数
sum(case when behavior_type = 'buy' then 1 else 0 end) as buy --购买数
from user_behavior
group by user_id;
4
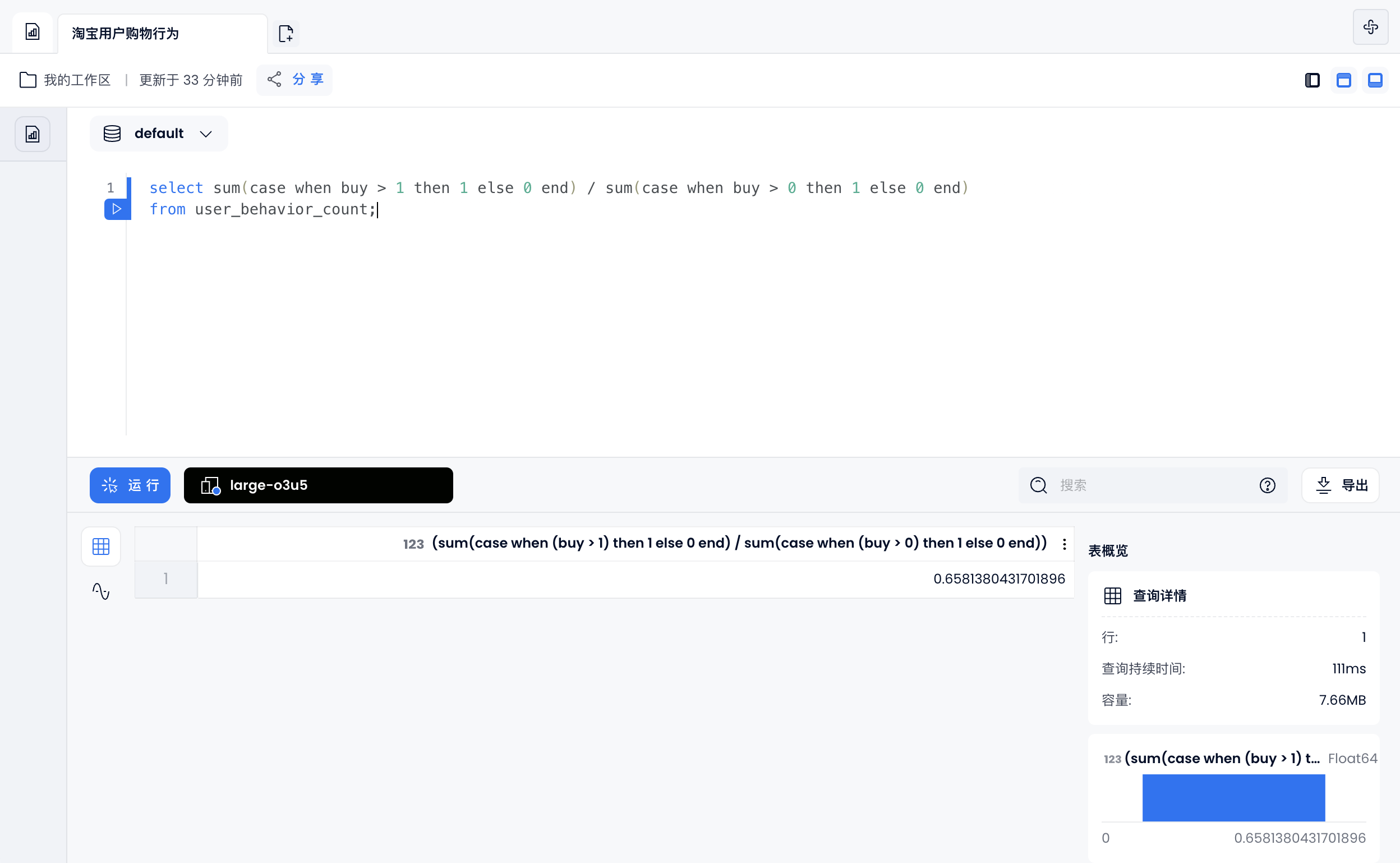
复购率:两次或两次以上购买的用户占购买用户的比例
select sum(case when buy > 1 then 1 else 0 end) / sum(case when buy > 0 then 1 else 0 end)
from user_behavior_count;
用户行为转换率
1
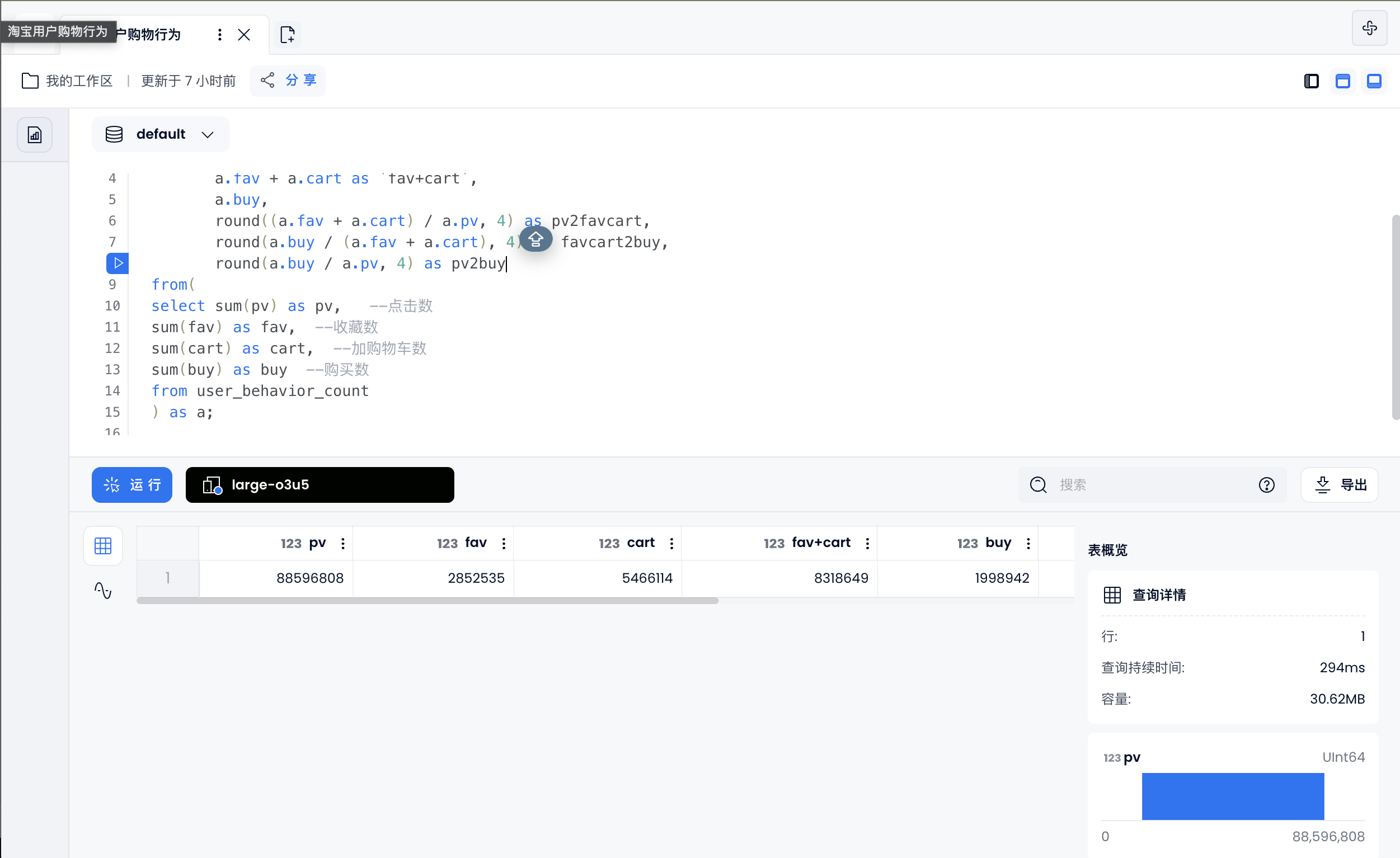
点击/(加购物车 + 收藏)/购买,各环节转化率
select a.pv,
a.fav,
a.cart,
a.fav + a.cart as `fav+cart`,
a.buy,
round((a.fav + a.cart) / a.pv, 4) as pv2favcart,
round(a.buy / (a.fav + a.cart), 4) as favcart2buy,
round(a.buy / a.pv, 4) as pv2buy
from(
select sum(pv) as pv, --点击数
sum(fav) as fav, --收藏数
sum(cart) as cart, --加购物车数
sum(buy) as buy --购买数
from user_behavior_count
) as a;
2
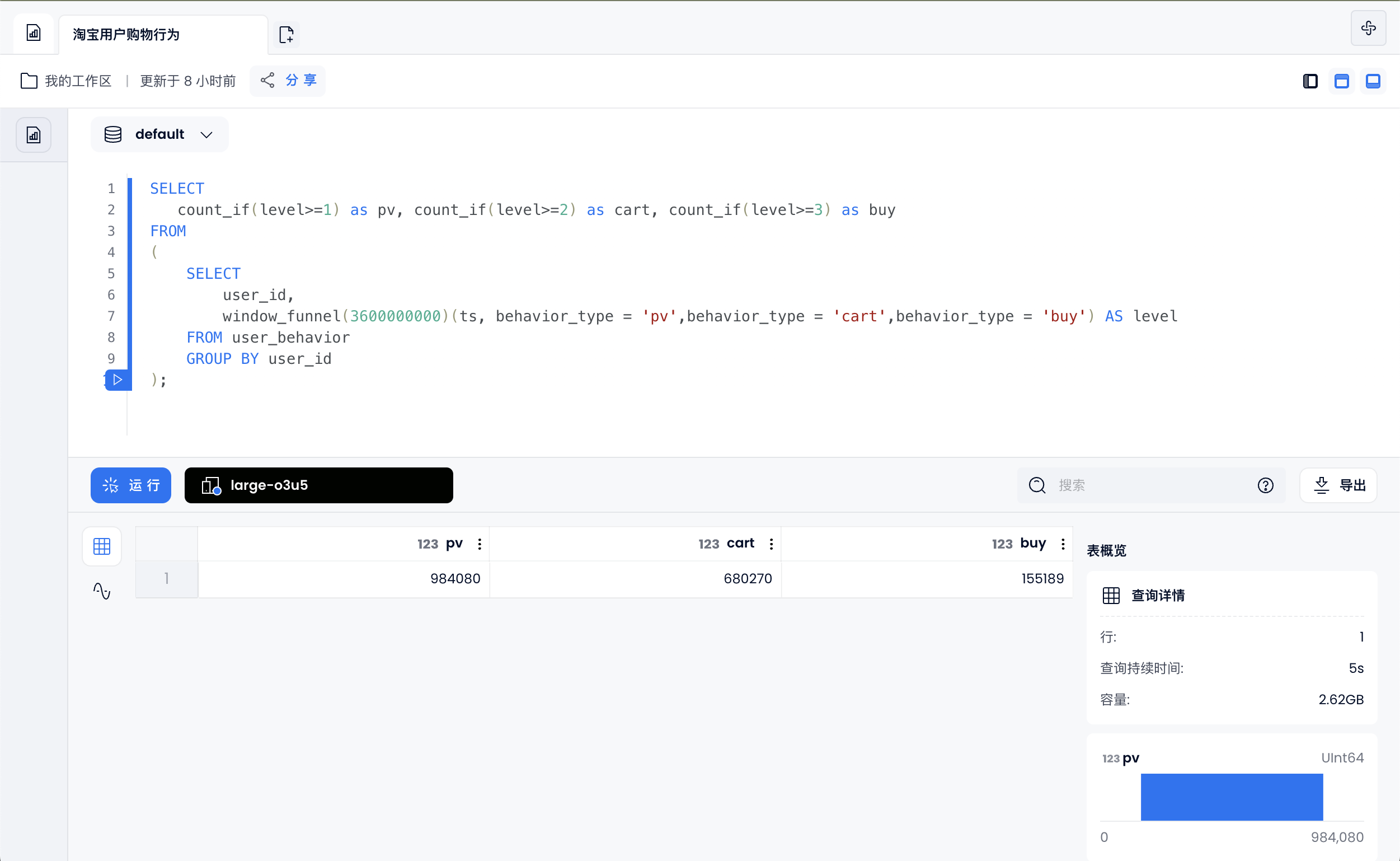
计算一个小时完成浏览->添加到购物->并支付的用户
SELECT
count_if(level>=1) as pv, count_if(level>=2) as cart, count_if(level>=3) as buy
FROM
(
SELECT
user_id,
window_funnel(3600000000)(ts, behavior_type = 'pv',behavior_type = 'cart',behavior_type = 'buy') AS level
FROM user_behavior
GROUP BY user_id
);
用户行为习惯
1
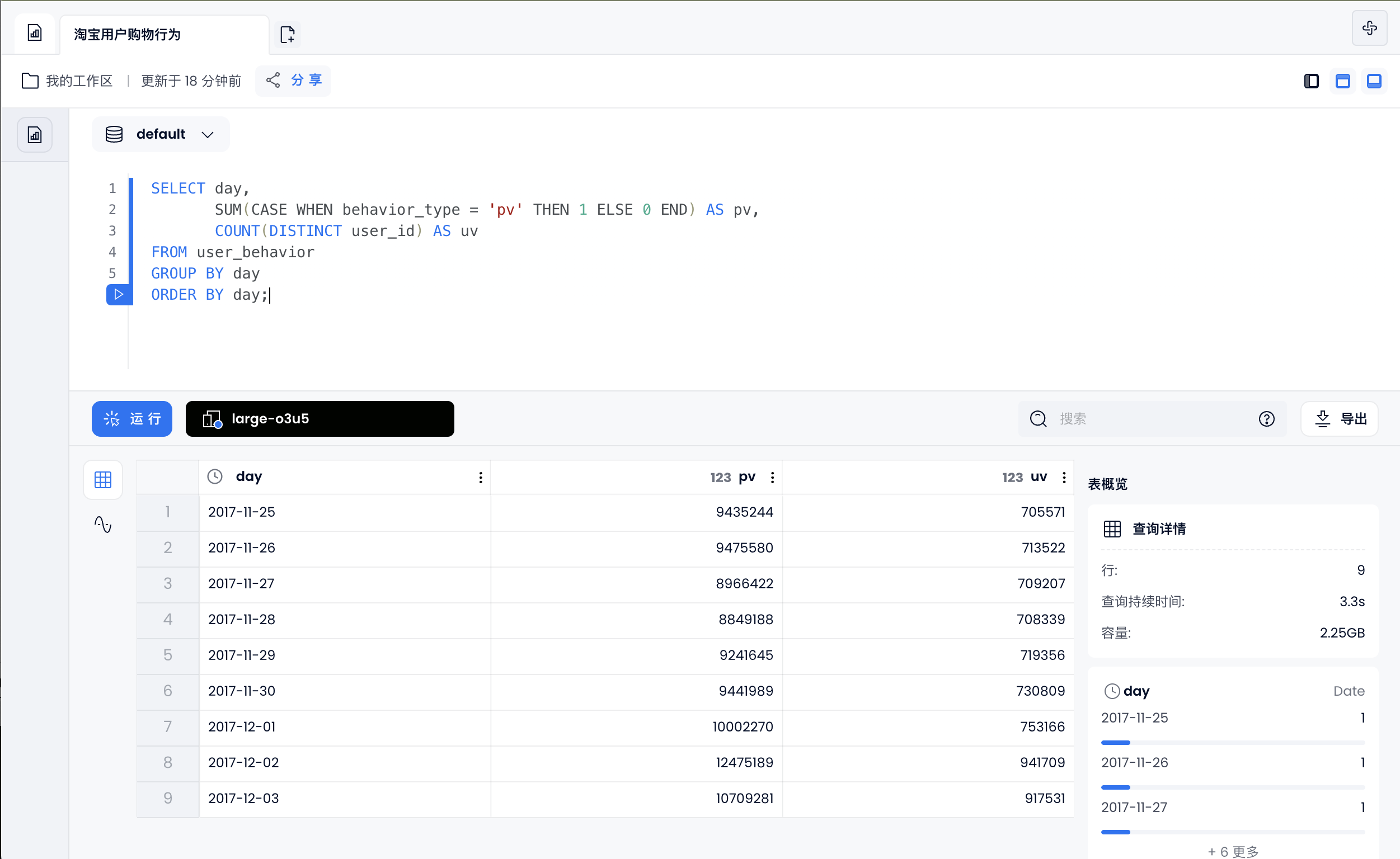
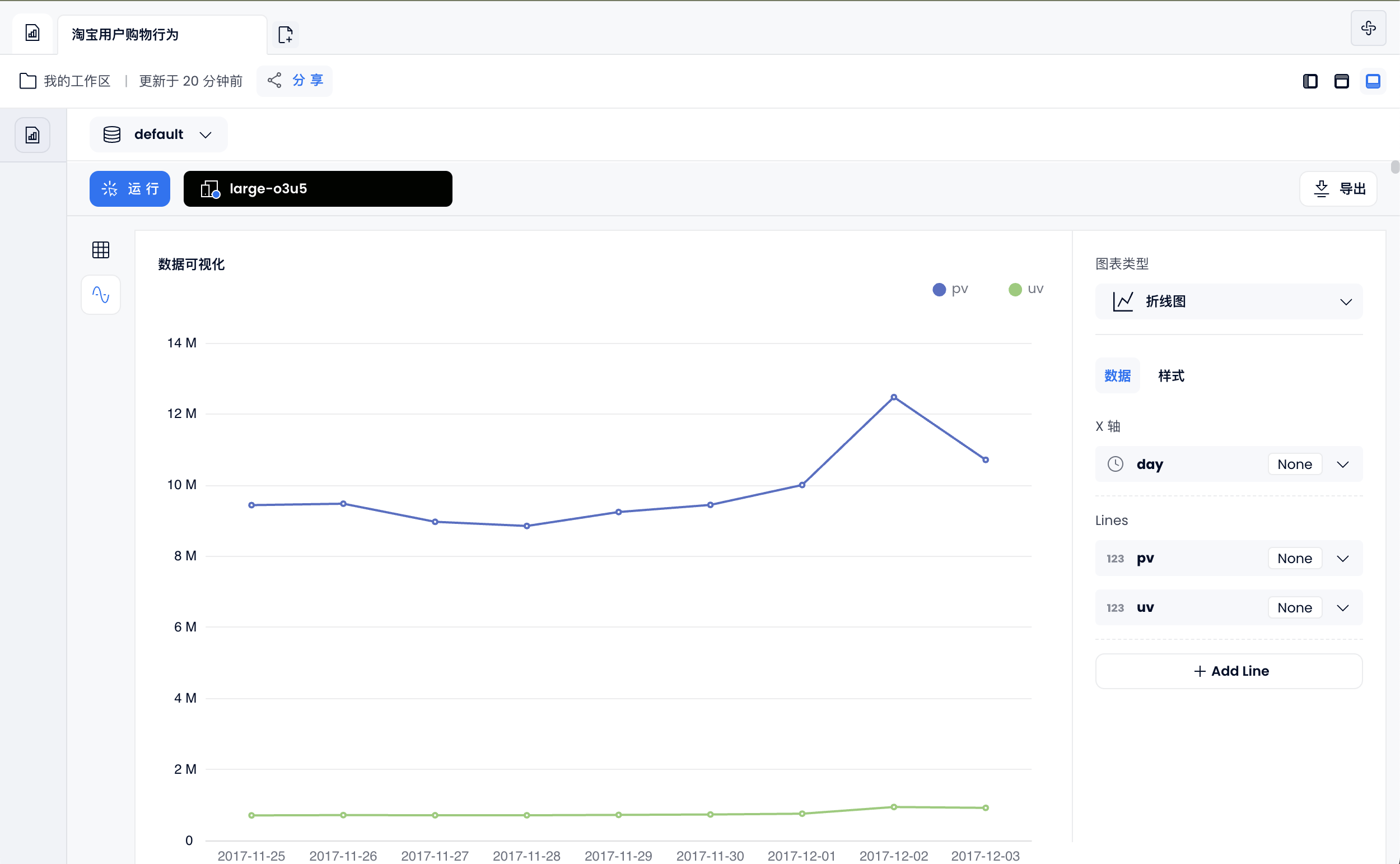
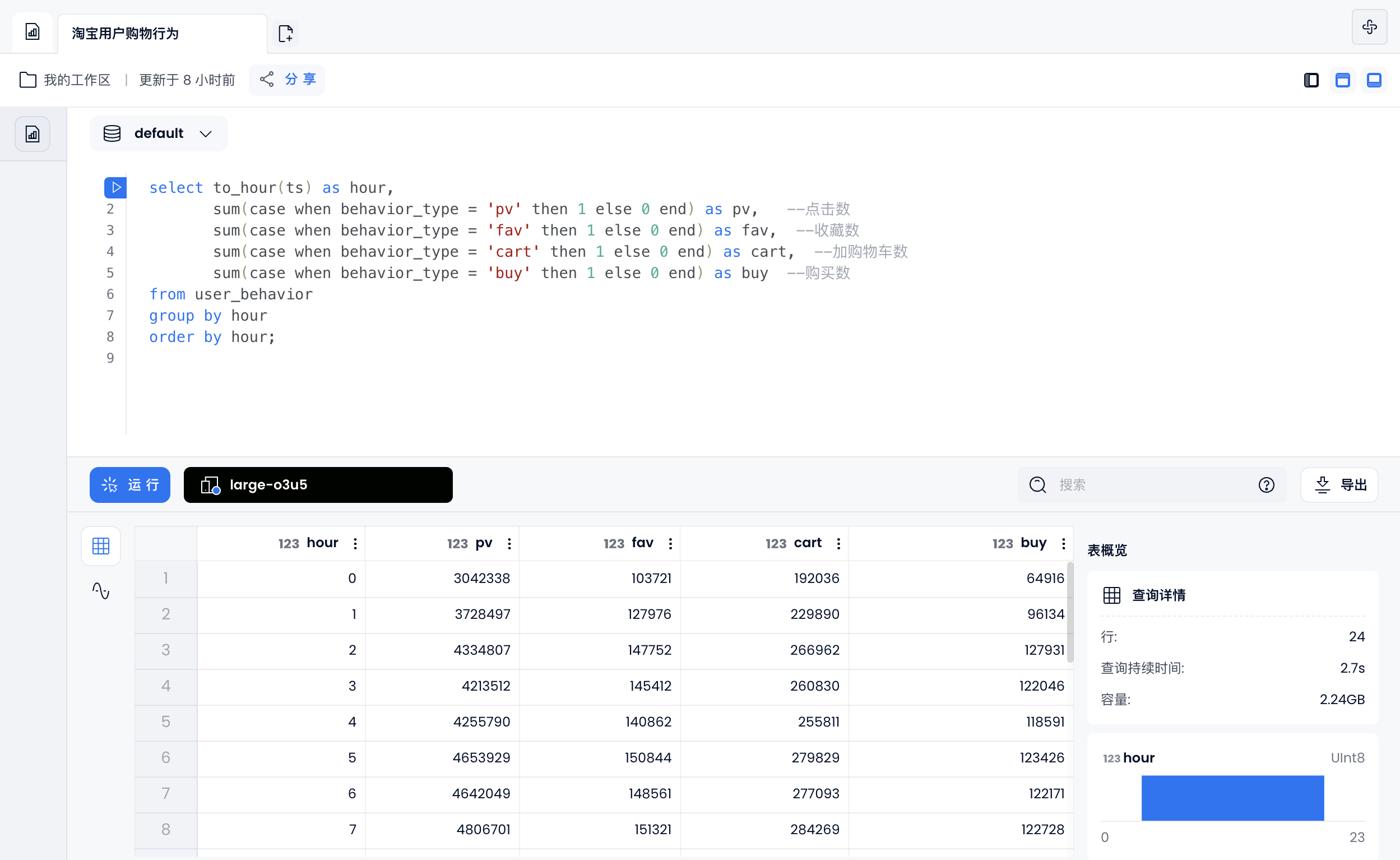
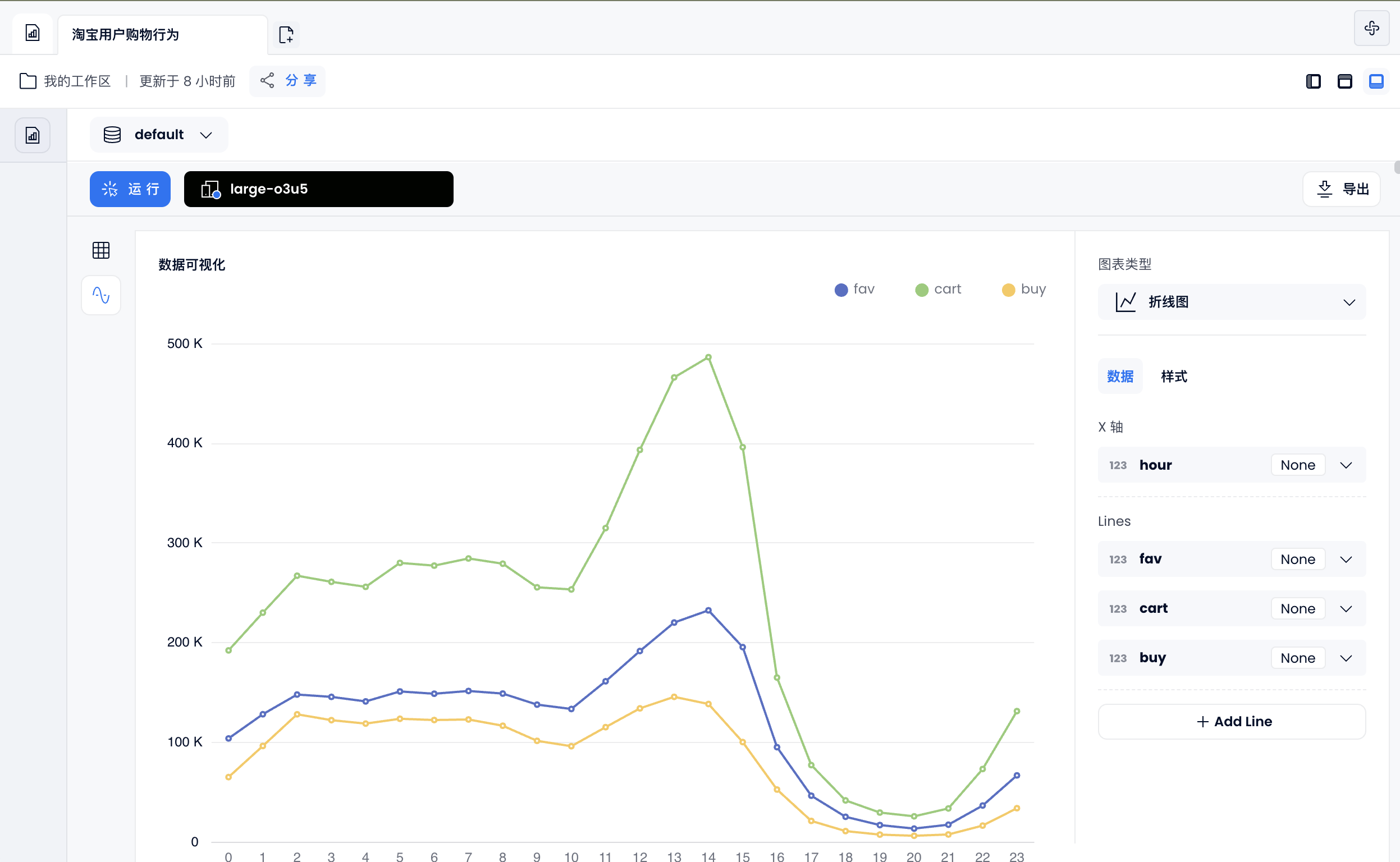
每天用户购物行为
select to_hour(ts) as hour,
sum(case when behavior_type = 'pv' then 1 else 0 end) as pv, --点击数
sum(case when behavior_type = 'fav' then 1 else 0 end) as fav, --收藏数
sum(case when behavior_type = 'cart' then 1 else 0 end) as cart, --加购物车数
sum(case when behavior_type = 'buy' then 1 else 0 end) as buy --购买数
from user_behavior
group by hour
order by hour;
也可以通过 使用仪表盘 功能,生成折线图:
2
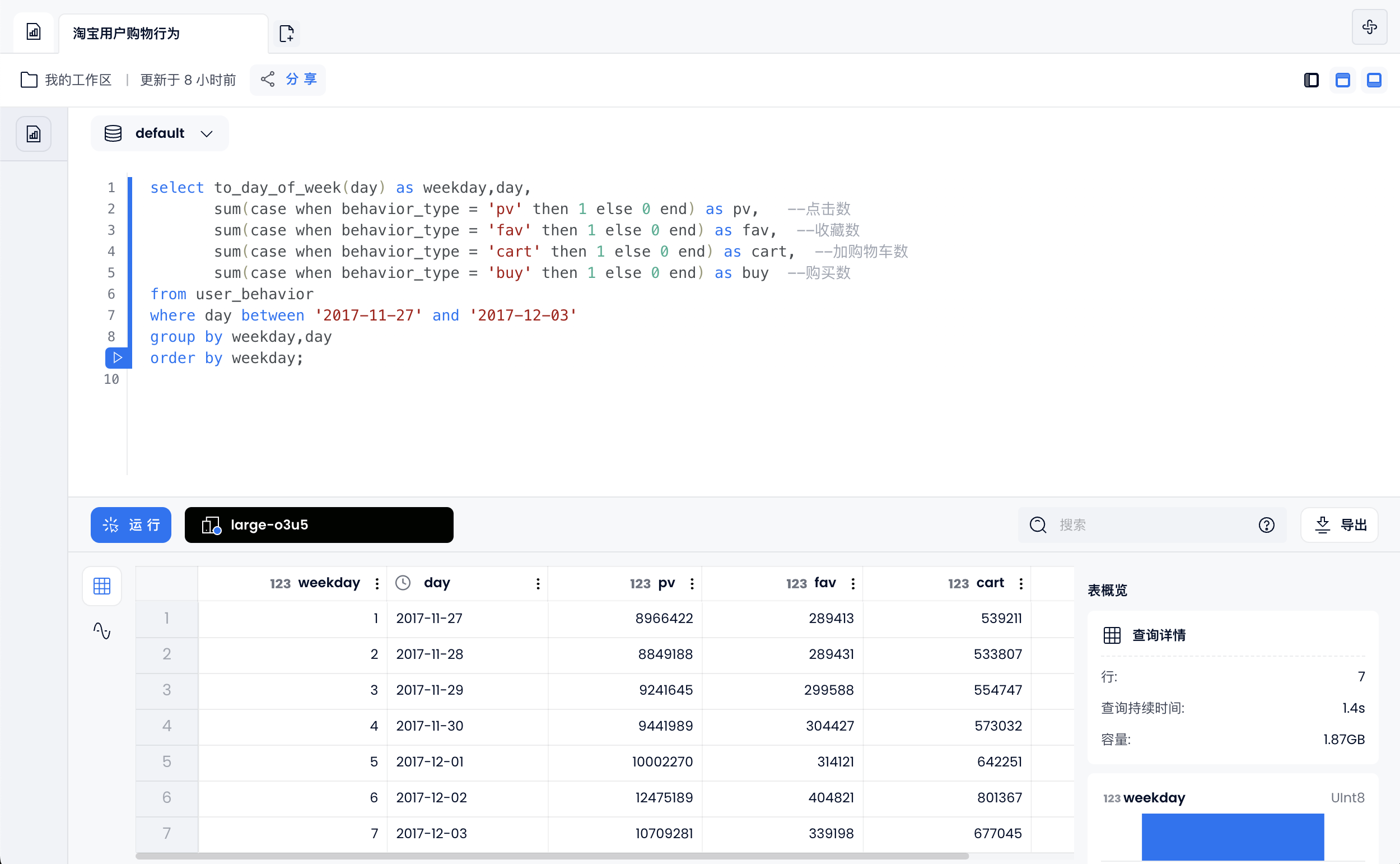
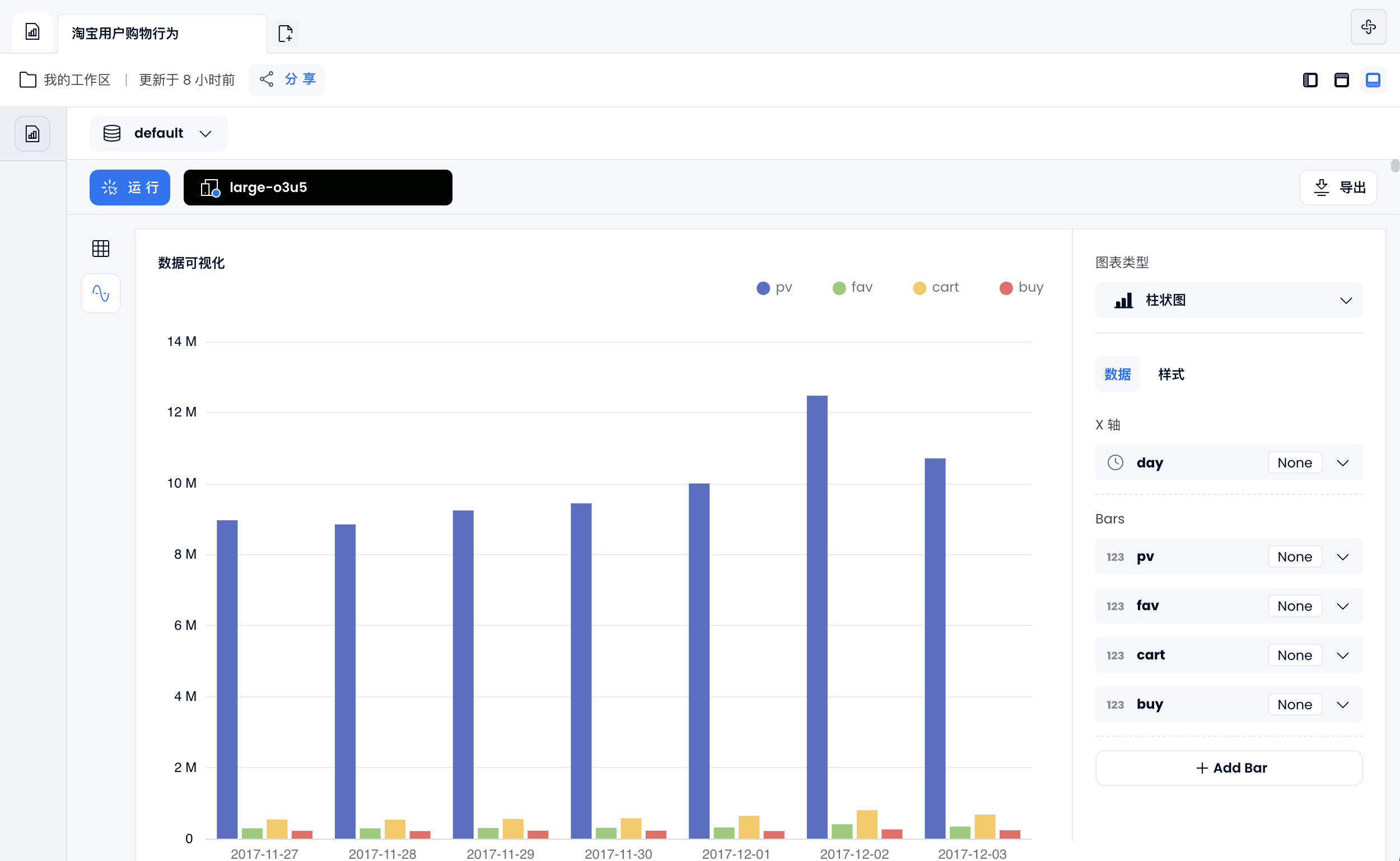
每周用户购物行为
select to_day_of_week(day) as weekday,day,
sum(case when behavior_type = 'pv' then 1 else 0 end) as pv, --点击数
sum(case when behavior_type = 'fav' then 1 else 0 end) as fav, --收藏数
sum(case when behavior_type = 'cart' then 1 else 0 end) as cart, --加购物车数
sum(case when behavior_type = 'buy' then 1 else 0 end) as buy --购买数
from user_behavior
where day between '2017-11-27' and '2017-12-03'
group by weekday,day
order by weekday;
也可以通过 使用仪表盘 功能,生成柱状图:
基于 RFM 模型找出有价值用户
RFM 模型是衡量客户价值和客户创利能力的重要工具和手段,其中由 3 个要素构成了数据分析最好的指标:
- R-Recency(最近一次购买时间)
- F-Frequency(消费频率)
- M-Money(消费金额)
1
R-Recency(最近购买时间):R 值越高,用户越活跃
select user_id,
to_date('2017-12-04') - max(day) as R,
dense_rank() over(order by (to_date('2017-12-04') - max(day))) as R_rank
from user_behavior
where behavior_type = 'buy'
group by user_id
limit 10;
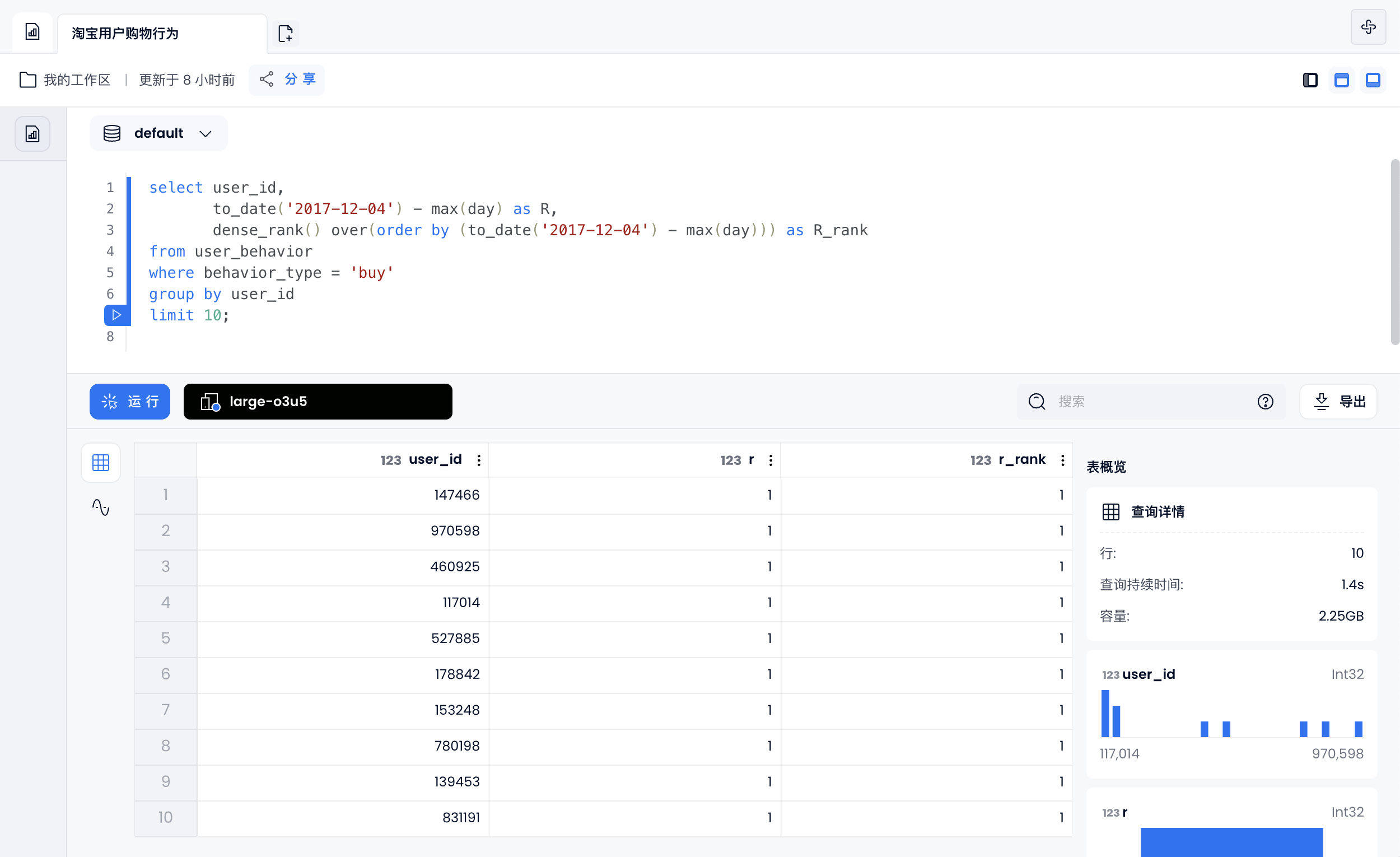
2
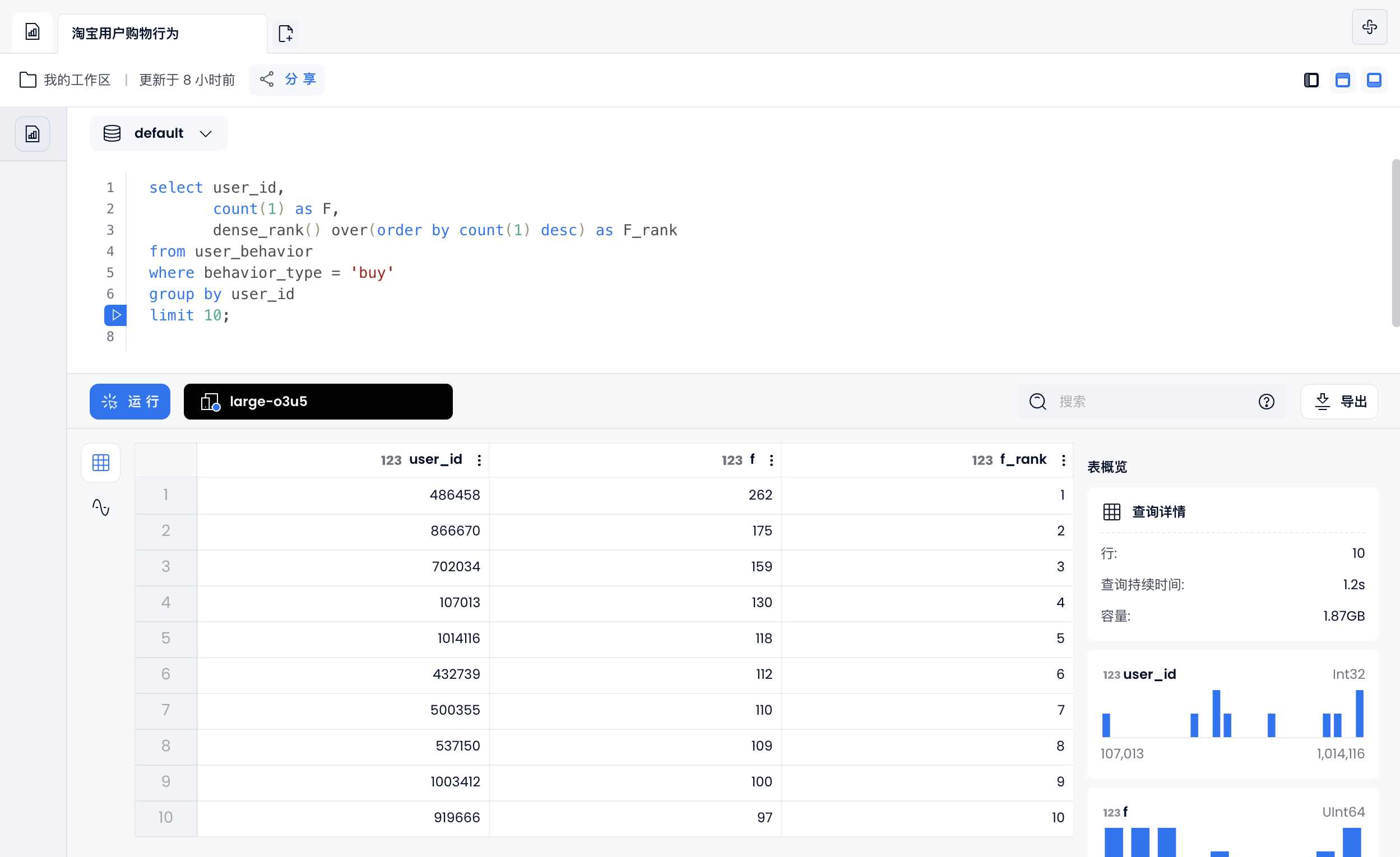
F-Frequency(消费频率):F 值越高,用户越忠诚
select user_id,
count(1) as F,
dense_rank() over(order by count(1) desc) as F_rank
from user_behavior
where behavior_type = 'buy'
group by user_id
limit 10;
3
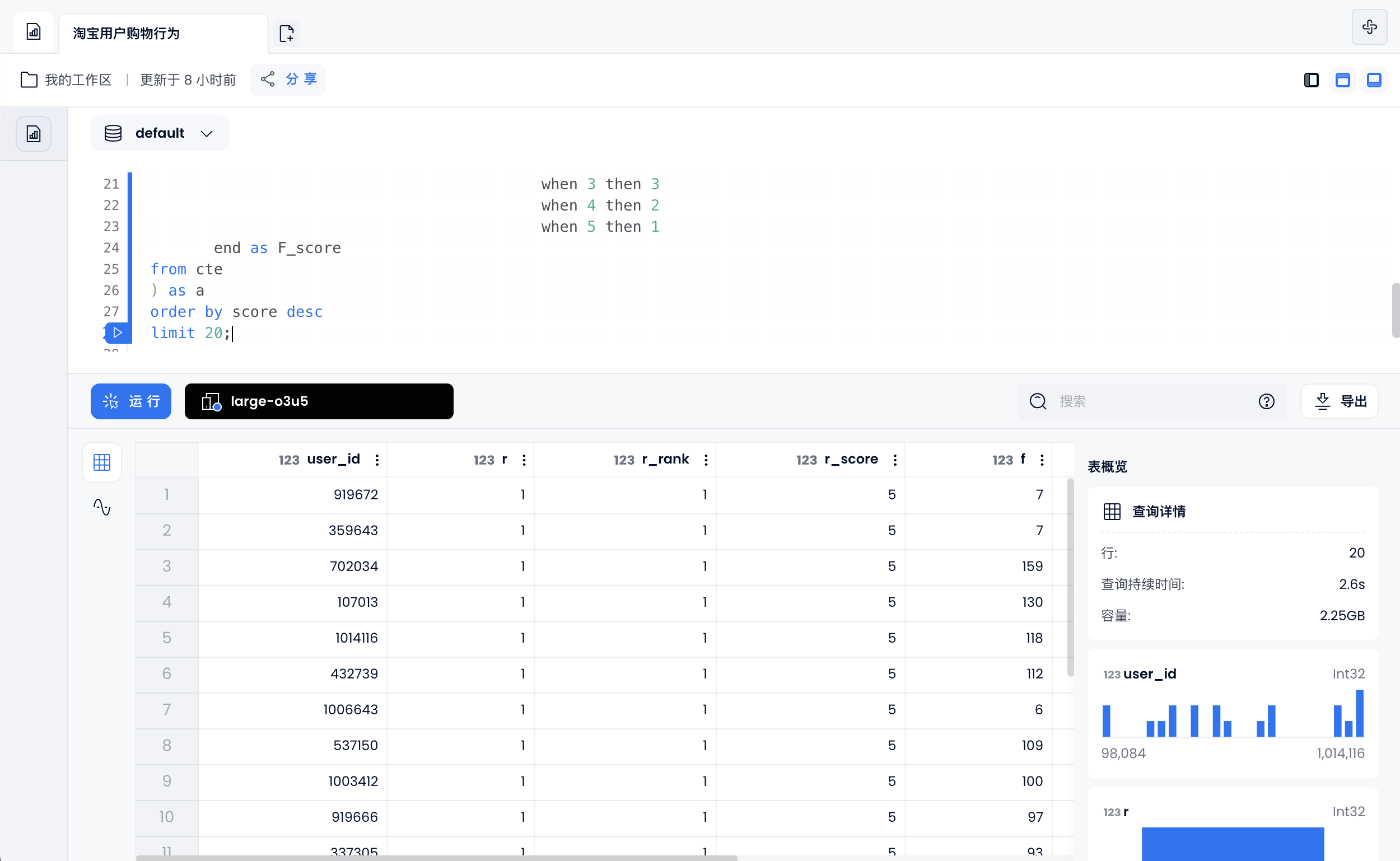
用户分组
对有购买行为的用户按照排名进行分组,共划分为 5 组:
- 前 1/5 的用户打 5 分
- 前 1/5 - 2/5 的用户打 4 分
- 前 2/5 - 3/5 的用户打 3 分
- 前 3/5 - 4/5 的用户打 2 分
- 其余用户打 1 分
按照这个规则分别对用户时间间隔排名打分和购买频率排名打分,最后把两个分数合并在一起作为该名用户的最终评分。
with cte as(
select user_id,
to_date('2017-12-04') - max(day) as R,
dense_rank() over(order by (to_date('2017-12-04') - max(day))) as R_rank,
count(1) as F,
dense_rank() over(order by count(1) desc) as F_rank
from user_behavior
where behavior_type = 'buy'
group by user_id)
select user_id, R, R_rank, R_score, F, F_rank, F_score, R_score + F_score AS score
from(
select *,
case ntile(5) over(order by R_rank) when 1 then 5
when 2 then 4
when 3 then 3
when 4 then 2
when 5 then 1
end as R_score,
case ntile(5) over(order by F_rank) when 1 then 5
when 2 then 4
when 3 then 3
when 4 then 2
when 5 then 1
end as F_score
from cte
) as a
order by score desc
limit 20;
商品维度分析
1
销量最高的商品
select item_id ,
sum(case when behavior_type = 'pv' then 1 else 0 end) as pv, --点击数
sum(case when behavior_type = 'fav' then 1 else 0 end) as fav, --收藏数
sum(case when behavior_type = 'cart' then 1 else 0 end) as cart, --加购物车数
sum(case when behavior_type = 'buy' then 1 else 0 end) as buy --购买数
from user_behavior
group by item_id
order by buy desc
limit 10;

2
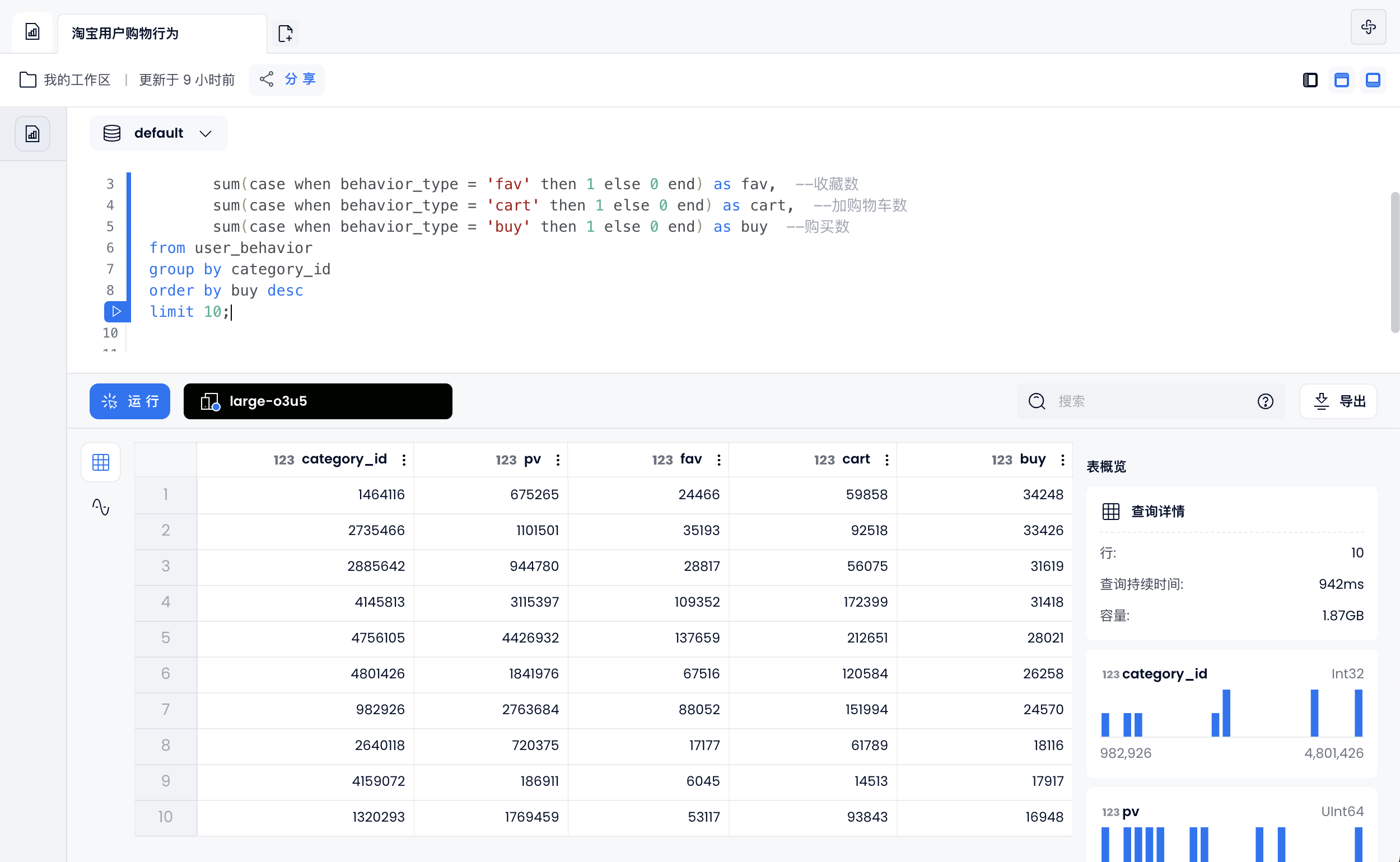
销量最高的商品类别
select category_id ,
sum(case when behavior_type = 'pv' then 1 else 0 end) as pv, --点击数
sum(case when behavior_type = 'fav' then 1 else 0 end) as fav, --收藏数
sum(case when behavior_type = 'cart' then 1 else 0 end) as cart, --加购物车数
sum(case when behavior_type = 'buy' then 1 else 0 end) as buy --购买数
from user_behavior
group by category_id
order by buy desc
limit 10;
用户留存分析
开始前,创建表格"day_users"并插入数据:
create table day_users(
day date,
users bitmap);
insert into day_users select day, build_bitmap(list(user_id::UInt64)) from user_behavior group by day;

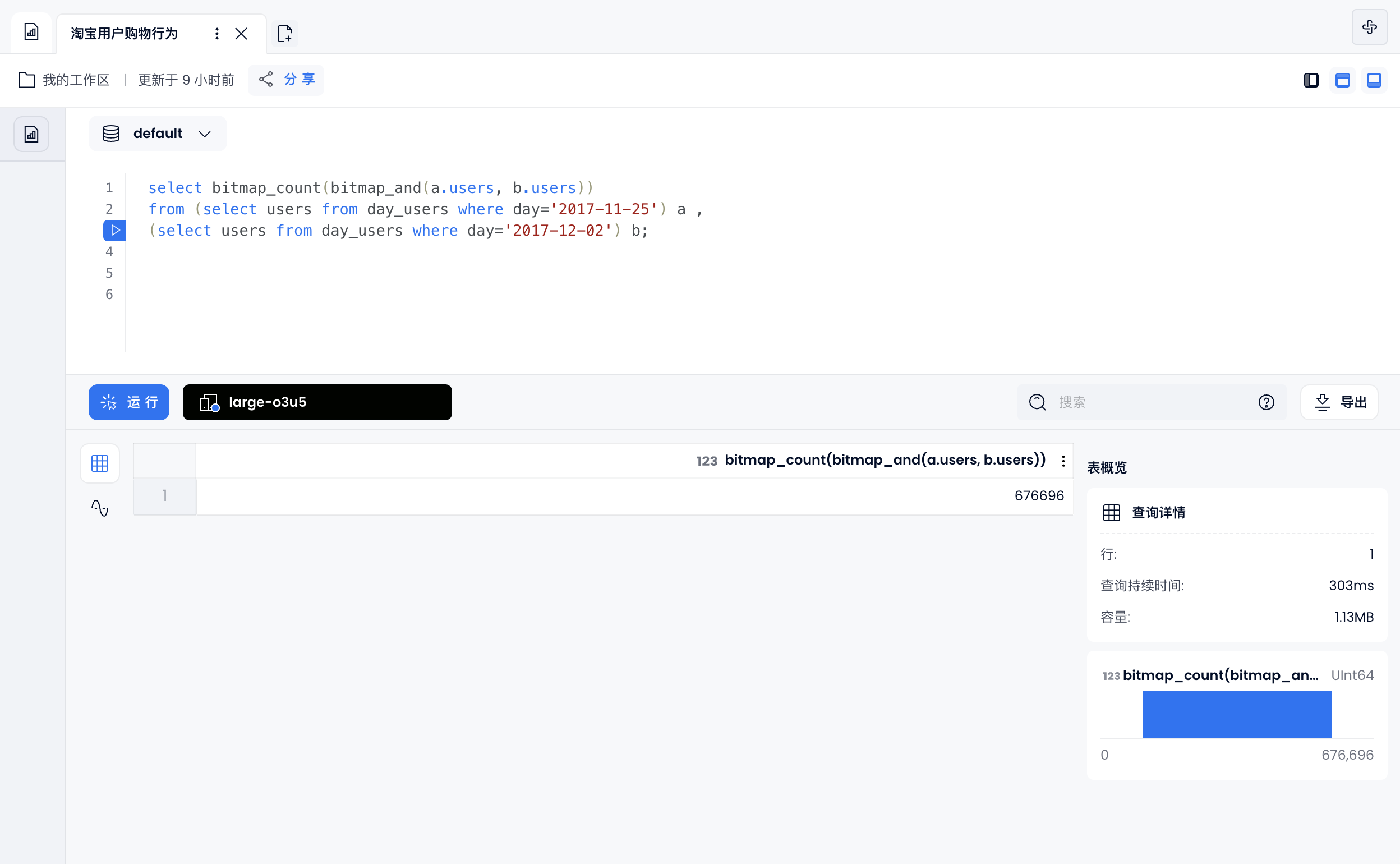
2
相对留存
这里计算相对于 11 月 23 日,12 月 2 号还在使用淘宝用户:
select bitmap_count(bitmap_and(a.users, b.users))
from (select users from day_users where day='2017-11-25') a ,
(select users from day_users where day='2017-12-02') b;
3
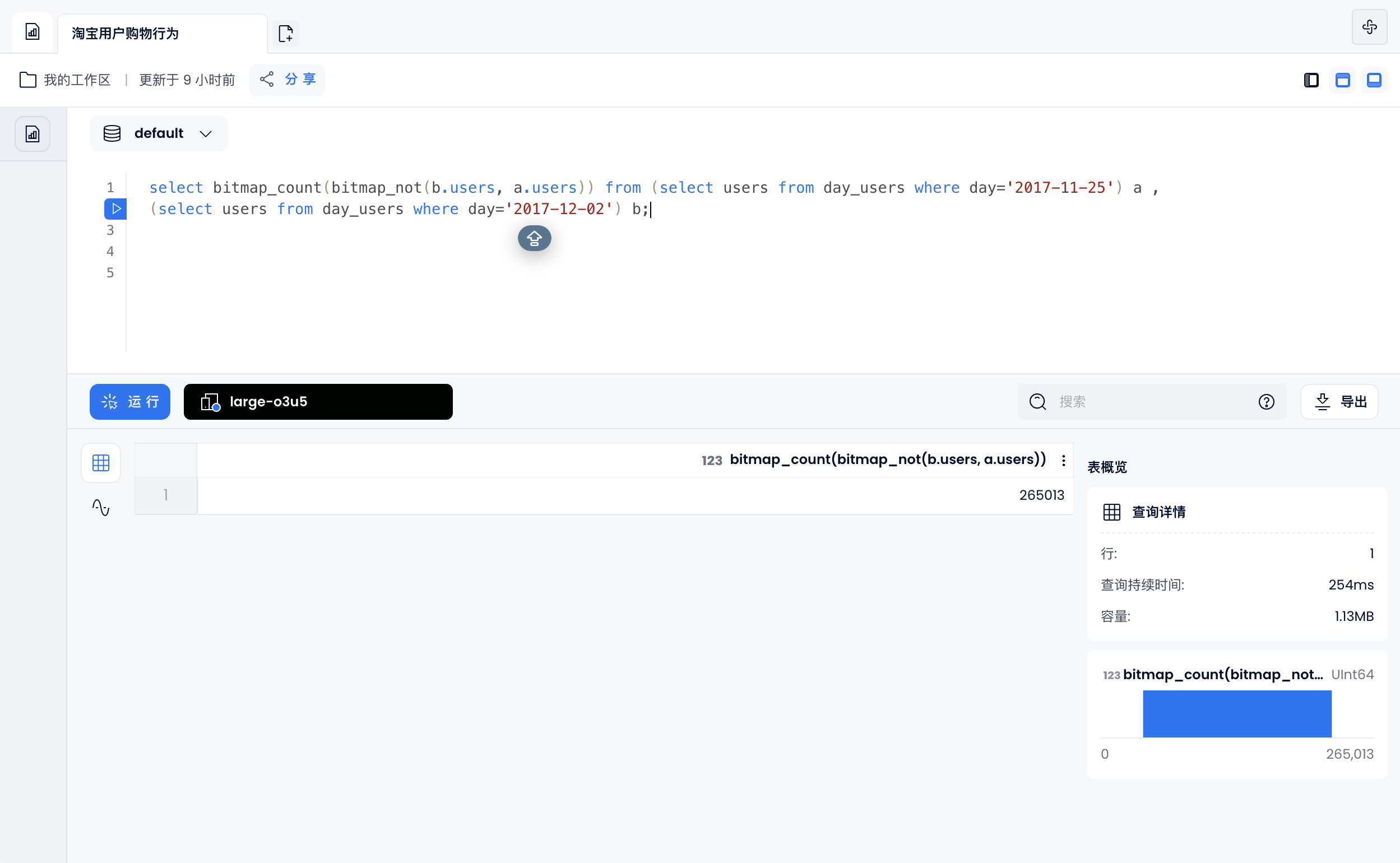
相对新增
select bitmap_count(bitmap_not(b.users, a.users)) from (select users from day_users where day='2017-11-25') a ,
(select users from day_users where day='2017-12-02') b;