COPY INTO <table>
COPY INTO 允许你从以下任一位置的文件中加载数据:
- 用户 / 内部 / 外部 Stage:关于 Databend 中的 Stage,请参阅 什么是 Stage?。
- 在存储服务中创建的 Bucket 或容器。
- 可通过 URL(以 "https://..." 开头)访问文件的远程服务器。
- IPFS 和 Hugging Face 仓库。
另请参阅:COPY INTO <location>
语法
/* 标准数据加载 */
COPY INTO [<database_name>.]<table_name> [ ( <col_name> [ , <col_name> ... ] ) ]
FROM { userStage | internalStage | externalStage | externalLocation }
[ FILES = ( '<file_name>' [ , '<file_name>' ] [ , ... ] ) ]
[ PATTERN = '<regex_pattern>' ]
[ FILE_FORMAT = (
FORMAT_NAME = '<your-custom-format>'
| TYPE = { CSV | TSV | NDJSON | PARQUET | ORC | AVRO } [ formatTypeOptions ]
) ]
[ copyOptions ]
/* 带转换的数据加载 */
COPY INTO [<database_name>.]<table_name> [ ( <col_name> [ , <col_name> ... ] ) ]
FROM (
SELECT {
[<alias>.]<column> [, [<alias>.]<column> ...] -- 按名称查询列
| [<alias>.]$<col_position> [, [<alias>.]$<col_position> ...] -- 按位置查询列
| [<alias>.]$1[:<column>] [, [<alias>.]$1[:<column>] ...] -- 将行作为 Variant 查询
} ]
FROM {@<stage_name>[/<path>] | '<uri>'}
)
[ FILES = ( '<file_name>' [ , '<file_name>' ] [ , ... ] ) ]
[ PATTERN = '<regex_pattern>' ]
[ FILE_FORMAT = (
FORMAT_NAME = '<your-custom-format>'
| TYPE = { CSV | TSV | NDJSON | PARQUET | ORC | AVRO } [ formatTypeOptions ]
) ]
[ copyOptions ]
从 Databend v1.2.890-nightly 开始,TEXT 可在 FILE_FORMAT 中作为 TSV 的别名使用。较旧版本的 Server 可能不支持 TYPE = TEXT,因此本页在语法和示例中仍使用 TSV 以保持兼容性。
其中:
userStage ::= @~[/<path>]
internalStage ::= @<internal_stage_name>[/<path>]
externalStage ::= @<external_stage_name>[/<path>]
externalLocation ::=
/* Amazon S3 兼容存储 */
's3://<bucket>[/<path>]'
CONNECTION = (
[ CONNECTION_NAME = '<connection-name>' ]
| [ ENDPOINT_URL = '<endpoint-url>' ]
[ ACCESS_KEY_ID = '<your-access-key-ID>' ]
[ SECRET_ACCESS_KEY = '<your-secret-access-key>' ]
[ ENABLE_VIRTUAL_HOST_STYLE = TRUE | FALSE ]
[ MASTER_KEY = '<your-master-key>' ]
[ REGION = '<region>' ]
[ SECURITY_TOKEN = '<security-token>' ]
[ ROLE_ARN = '<role-arn>' ]
[ EXTERNAL_ID = '<external-id>' ]
)
/* Azure Blob Storage */
| 'azblob://<container>[/<path>]'
CONNECTION = (
[ CONNECTION_NAME = '<connection-name>' ]
| ENDPOINT_URL = '<endpoint-url>'
ACCOUNT_NAME = '<account-name>'
ACCOUNT_KEY = '<account-key>'
)
/* Google Cloud Storage */
| 'gcs://<bucket>[/<path>]'
CONNECTION = (
[ CONNECTION_NAME = '<connection-name>' ]
| CREDENTIAL = '<your-base64-encoded-credential>'
)
/* 阿里云 OSS */
| 'oss://<bucket>[/<path>]'
CONNECTION = (
[ CONNECTION_NAME = '<connection-name>' ]
| ACCESS_KEY_ID = '<your-ak>'
ACCESS_KEY_SECRET = '<your-sk>'
ENDPOINT_URL = '<endpoint-url>'
[ PRESIGN_ENDPOINT_URL = '<presign-endpoint-url>' ]
)
/* 腾讯云对象存储 */
| 'cos://<bucket>[/<path>]'
CONNECTION = (
[ CONNECTION_NAME = '<connection-name>' ]
| SECRET_ID = '<your-secret-id>'
SECRET_KEY = '<your-secret-key>'
ENDPOINT_URL = '<endpoint-url>'
)
/* 远程文件 */
| 'https://<url>'
/* IPFS */
| 'ipfs://<your-ipfs-hash>'
CONNECTION = (ENDPOINT_URL = 'https://<your-ipfs-gateway>')
/* Hugging Face */
| 'hf://<repo-id>[/<path>]'
CONNECTION = (
[ REPO_TYPE = 'dataset' | 'model' ]
[ REVISION = '<revision>' ]
[ TOKEN = '<your-api-token>' ]
)
formatTypeOptions ::=
/* 所有格式通用选项 */
[ COMPRESSION = AUTO | GZIP | BZ2 | BROTLI | ZSTD | DEFLATE | RAW_DEFLATE | XZ | NONE ]
/* CSV 专用选项 */
[ RECORD_DELIMITER = '<character>' ]
[ FIELD_DELIMITER = '<character>' ]
[ SKIP_HEADER = <integer> ]
[ QUOTE = '<character>' ]
[ ESCAPE = '<character>' ]
[ NAN_DISPLAY = '<string>' ]
[ NULL_DISPLAY = '<string>' ]
[ ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE | FALSE ]
[ EMPTY_FIELD_AS = null | string | field_default ]
[ BINARY_FORMAT = HEX | BASE64 ]
[ TRIM_SPACE = TRUE | FALSE ]
[ ENCODING = '<encoding_label>' ]
[ ENCODING_ERROR_MODE = STRICT | REPLACE ]
/* TSV 专用选项 */
[ RECORD_DELIMITER = '<character>' ]
[ FIELD_DELIMITER = '<character>' ]
[ TRIM_SPACE = TRUE | FALSE ]
[ ENCODING = '<encoding_label>' ]
[ ENCODING_ERROR_MODE = STRICT | REPLACE ]
/* NDJSON 专用选项 */
[ NULL_FIELD_AS = NULL | FIELD_DEFAULT ]
[ MISSING_FIELD_AS = ERROR | NULL | FIELD_DEFAULT ]
[ NULL_IF = ('value1', 'value2', ...) ]
[ ALLOW_DUPLICATE_KEYS = TRUE | FALSE ]
/* PARQUET 专用选项 */
[ MISSING_FIELD_AS = ERROR | FIELD_DEFAULT ]
[ NULL_IF = ('value1', 'value2', ...) ]
[ USE_LOGIC_TYPE = TRUE | FALSE ]
/* ORC 专用选项 */
[ MISSING_FIELD_AS = ERROR | FIELD_DEFAULT ]
/* AVRO 专用选项 */
[ MISSING_FIELD_AS = ERROR | FIELD_DEFAULT ]
[ NULL_IF = ('value1', 'value2', ...) ]
[ USE_LOGIC_TYPE = TRUE | FALSE ]
copyOptions ::=
[ PURGE = <bool> ]
[ FORCE = <bool> ]
[ DISABLE_VARIANT_CHECK = <bool> ]
[ ON_ERROR = { continue | abort | abort_N } ]
[ MAX_FILES = <num> ]
[ RETURN_FAILED_ONLY = <bool> ]
[ COLUMN_MATCH_MODE = { case-sensitive | case-insensitive } ]
[ SCHEMA_EVOLUTION = (
[ SAMPLE_FILES = AUTO | <positive_integer> ]
[ , SAMPLE_RECORDS_PER_FILE = AUTO | <positive_integer> ]
[ , SAMPLE_TOTAL_RECORDS = AUTO | <positive_integer> ]
) ]
关键参数
-
FILES:指定一个或多个待加载文件名(以逗号分隔)。
-
PATTERN:基于 PCRE2 的正则表达式模式字符串,用于匹配文件名。从 Stage 加载时,该模式匹配的是
@<stage_name>[/<path>]之后的文件路径部分。参见 使用 PATTERN 过滤 Stage 文件 和 示例 4:使用模式过滤文件。
格式类型选项
FILE_FORMAT 参数支持多种文件类型,每种类型都有专属的格式选项。下表列出各支持格式的可用选项。完整说明请参见 文件格式选项。
- 通用选项
- CSV
- TSV
- NDJSON
- PARQUET
- ORC
- AVRO
以下选项适用于所有文件格式:
| 选项 | 描述 | 取值 | 默认值 |
|---|---|---|---|
| COMPRESSION | 数据文件的压缩算法 | AUTO, GZIP, BZ2, BROTLI, ZSTD, DEFLATE, RAW_DEFLATE, XZ, NONE | AUTO |
| 选项 | 描述 | 默认值 |
|---|---|---|
| RECORD_DELIMITER | 分隔记录的字符 | 换行符 |
| FIELD_DELIMITER | 分隔字段的字符 | 逗号 (,) |
| SKIP_HEADER | 跳过的标题行数 | 0 |
| QUOTE | 用于引用字段的字符 | 双引号 (") |
| ESCAPE | 用于转义被引用字段的字符 | NONE |
| NAN_DISPLAY | 表示 NaN 值的字符串 | NaN |
| NULL_DISPLAY | 表示 NULL 值的字符串 | \N |
| ERROR_ON_COLUMN_COUNT_MISMATCH | 列数不匹配时报错 | TRUE |
| EMPTY_FIELD_AS | 空字段的处理方式 | null |
| BINARY_FORMAT | 二进制数据的编码格式(HEX 或 BASE64) | HEX |
| TRIM_SPACE | 去除字段前后 ASCII 空白字符 | FALSE |
| ENCODING | 源文件字符集编码 | UTF-8 |
| ENCODING_ERROR_MODE | 无效字节的处理方式:STRICT 或 REPLACE | STRICT |
| 选项 | 描述 | 默认值 |
|---|---|---|
| RECORD_DELIMITER | 分隔记录的字符 | 换行符 |
| FIELD_DELIMITER | 分隔字段的字符 | 制表符 (\t) |
| SKIP_HEADER | 跳过的标题行数 | 0 |
| TRIM_SPACE | 去除字段前后 ASCII 空白字符 | FALSE |
| NAN_DISPLAY | 表示 NaN 值的字符串 | NaN |
| NULL_DISPLAY | 表示 NULL 值的字符串 | \N |
| EMPTY_FIELD_AS | 空字段的处理方式 | FIELD_DEFAULT |
| ERROR_ON_COLUMN_COUNT_MISMATCH | 列数不匹配时报错 | TRUE |
| ENCODING | 源文件字符集编码 | UTF-8 |
| ENCODING_ERROR_MODE | 无效字节的处理方式:STRICT 或 REPLACE | STRICT |
| 选项 | 描述 | 默认值 |
|---|---|---|
| NULL_FIELD_AS | 空字段的处理方式 | NULL |
| MISSING_FIELD_AS | 缺失字段的处理方式 | ERROR |
| NULL_IF | 视为 NULL 的字符串列表 | 空 |
| ALLOW_DUPLICATE_KEYS | 是否允许对象键重复 | FALSE |
| 选项 | 描述 | 默认值 |
|---|---|---|
| MISSING_FIELD_AS | 缺失字段的处理方式 | ERROR |
| NULL_IF | 视为 NULL 的字符串列表 | 空 |
| USE_LOGIC_TYPE | 使用 Parquet 逻辑类型推断列类型 | TRUE |
| 选项 | 描述 | 默认值 |
|---|---|---|
| MISSING_FIELD_AS | 缺失字段的处理方式 | ERROR |
| 选项 | 描述 | 默认值 |
|---|---|---|
| MISSING_FIELD_AS | 缺失字段的处理方式 | ERROR |
| NULL_IF | 视为 NULL 的字符串列表 | 空 |
| USE_LOGIC_TYPE | 使用 Avro 逻辑类型推断列类型 | TRUE |
复制选项
| 参数 | 描述 | 默认值 |
|---|---|---|
| PURGE | 成功加载后删除文件 | false |
| FORCE | 允许重新加载重复文件 | false(跳过重复) |
| DISABLE_VARIANT_CHECK | 将无效 JSON 替换为 null | false(无效 JSON 时报错) |
| ON_ERROR | 错误处理方式:continue、abort 或 abort_N | abort |
| MAX_FILES | 最大加载文件数(上限 15,000) | - |
| RETURN_FAILED_ONLY | 仅返回失败的文件 | false |
| COLUMN_MATCH_MODE | Parquet 列名匹配模式 | case-insensitive |
| SCHEMA_EVOLUTION | NDJSON 专用:用于推断目标表中缺失列的采样选项。要求目标表启用 ENABLE_SCHEMA_EVOLUTION = true,并且执行角色拥有目标表的 ALTER 权限。 | AUTO 采样 |
SCHEMA_EVOLUTION 选项
SCHEMA_EVOLUTION 控制 Databend 在加载前如何采样 staged NDJSON 文件。目标表启用 ENABLE_SCHEMA_EVOLUTION = true 后,可与 FILE_FORMAT = (TYPE = NDJSON ...) 搭配使用。
当从 Stage 或外部位置加载并触发 Schema Evolution 推断时,执行 COPY INTO <table> 的角色必须拥有目标表的 INSERT 和 ALTER 权限。基于查询的 COPY(例如 COPY INTO <table> FROM (SELECT ... FROM @stage))仍使用原有权限要求。
| 选项 | 描述 | 取值 |
|---|---|---|
| SAMPLE_FILES | 采样的 staged 文件数量。 | AUTO 或正整数 |
| SAMPLE_RECORDS_PER_FILE | 每个采样文件中最多采样的记录数。 | AUTO 或正整数 |
| SAMPLE_TOTAL_RECORDS | 所有采样文件中最多采样的记录总数。 | AUTO 或正整数 |
如果省略 SCHEMA_EVOLUTION,Databend 会对三个采样选项都使用 AUTO。当前 AUTO 行为最多采样 64 个文件、每个文件 1,000 条记录、总计 10,000 条记录。这些内部默认值未来版本可能会调整。如果加载结果对采样策略敏感,建议显式设置 SAMPLE_FILES、SAMPLE_RECORDS_PER_FILE 和 SAMPLE_TOTAL_RECORDS。如果采样遗漏了加载过程中出现的列,COPY 会失败并返回额外列名,你可以增大采样参数后重试。
导入大量数据(如日志)时,建议将 PURGE 和 FORCE 均设为 true,可高效导入数据且无需与 Meta 服务器交互(更新已复制文件集)。但请注意,这可能导致重复数据导入。
输出
COPY INTO 返回数据加载结果摘要,包含以下列:
| 列 | 类型 | 可空 | 描述 |
|---|---|---|---|
| FILE | VARCHAR | NO | 源文件的相对路径 |
| ROWS_LOADED | INT | NO | 从源文件加载的行数 |
| ERRORS_SEEN | INT | NO | 源文件中的错误行数 |
| FIRST_ERROR | VARCHAR | YES | 源文件中发现的第一个错误 |
| FIRST_ERROR_LINE | INT | YES | 第一个错误的行号 |
若 RETURN_FAILED_ONLY 设为 true,则仅输出加载失败的文件。
示例
对于外部存储源,建议使用预先创建的连接并通过 CONNECTION_NAME 参数引用,而非在 COPY 语句中直接指定凭据。该方式更安全、易维护且可复用。详见 CREATE CONNECTION。
示例 1:从 Stage 加载
以下示例展示如何从各类 Stage 向 Databend 加载数据:
- 用户 Stage
- 内部 Stage
- 外部 Stage
COPY INTO mytable
FROM @~
PATTERN = '.*[.]parquet'
FILE_FORMAT = (TYPE = PARQUET);
COPY INTO mytable
FROM @my_internal_stage
PATTERN = '.*[.]parquet'
FILE_FORMAT = (TYPE = PARQUET);
COPY INTO mytable
FROM @my_external_stage
PATTERN = '.*[.]parquet'
FILE_FORMAT = (TYPE = PARQUET);
示例 2:从外部位置加载
以下示例展示如何从各类外部源向 Databend 加载数据:
- Amazon S3
- Azure Blob Storage
- Google Cloud Storage
- 远程文件
- IPFS
本示例使用预创建连接从 Amazon S3 加载数据:
-- 先创建连接(仅需一次)
CREATE CONNECTION my_s3_conn
STORAGE_TYPE = 's3'
ACCESS_KEY_ID = '<your-access-key-ID>'
SECRET_ACCESS_KEY = '<your-secret-access-key>';
-- 使用连接加载数据
COPY INTO mytable
FROM 's3://mybucket/data.csv'
CONNECTION = (CONNECTION_NAME = 'my_s3_conn')
FILE_FORMAT = (
TYPE = CSV,
FIELD_DELIMITER = ',',
RECORD_DELIMITER = '\n',
SKIP_HEADER = 1
);
使用 IAM 角色(生产环境推荐)
-- 使用 IAM 角色创建连接(更安全,生产环境推荐)
CREATE CONNECTION my_iam_conn
STORAGE_TYPE = 's3'
ROLE_ARN = 'arn:aws:iam::123456789012:role/my_iam_role';
-- 使用 IAM 角色连接加载 CSV 文件
COPY INTO mytable
FROM 's3://mybucket/'
CONNECTION = (CONNECTION_NAME = 'my_iam_conn')
PATTERN = '.*[.]csv'
FILE_FORMAT = (
TYPE = CSV,
FIELD_DELIMITER = ',',
RECORD_DELIMITER = '\n',
SKIP_HEADER = 1
);
本示例连接 Azure Blob Storage 并将 'data.csv' 加载到 Databend:
-- 为 Azure Blob Storage 创建连接
CREATE CONNECTION my_azure_conn
STORAGE_TYPE = 'azblob'
ENDPOINT_URL = 'https://<account_name>.blob.core.windows.net'
ACCOUNT_NAME = '<account_name>'
ACCOUNT_KEY = '<account_key>';
-- 使用连接加载数据
COPY INTO mytable
FROM 'azblob://mybucket/data.csv'
CONNECTION = (CONNECTION_NAME = 'my_azure_conn')
FILE_FORMAT = (type = CSV);
本示例连接 Google Cloud Storage 并加载数据:
-- 为 Google Cloud Storage 创建连接
CREATE CONNECTION my_gcs_conn
STORAGE_TYPE = 'gcs'
CREDENTIAL = '<your-base64-encoded-credential>';
-- 使用连接加载数据
COPY INTO mytable
FROM 'gcs://mybucket/data.csv'
CONNECTION = (CONNECTION_NAME = 'my_gcs_conn')
FILE_FORMAT = (
TYPE = CSV,
FIELD_DELIMITER = ',',
RECORD_DELIMITER = '\n',
SKIP_HEADER = 1
);
本示例从三个远程 CSV 文件加载数据,出错时跳过文件:
COPY INTO mytable
FROM 'https://ci.databend.cn/dataset/stateful/ontime_200{6,7,8}_200.csv'
FILE_FORMAT = (type = CSV)
ON_ERROR = continue;
本示例从 IPFS 上的 CSV 文件加载数据:
COPY INTO mytable
FROM 'ipfs://<your-ipfs-hash>'
CONNECTION = (
ENDPOINT_URL = 'https://<your-ipfs-gateway>'
)
FILE_FORMAT = (
TYPE = CSV,
FIELD_DELIMITER = ',',
RECORD_DELIMITER = '\n',
SKIP_HEADER = 1
);
示例 3:加载压缩数据
本示例将 Amazon S3 上的 GZIP 压缩 CSV 文件加载到 Databend:
-- 为加载压缩数据创建连接
CREATE CONNECTION compressed_s3_conn
STORAGE_TYPE = 's3'
ACCESS_KEY_ID = '<your-access-key-ID>'
SECRET_ACCESS_KEY = '<your-secret-access-key>';
-- 使用连接加载 GZIP 压缩 CSV 文件
COPY INTO mytable
FROM 's3://mybucket/data.csv.gz'
CONNECTION = (CONNECTION_NAME = 'compressed_s3_conn')
FILE_FORMAT = (
TYPE = CSV,
FIELD_DELIMITER = ',',
RECORD_DELIMITER = '\n',
SKIP_HEADER = 1,
COMPRESSION = AUTO
);
示例 4:使用模式过滤文件
本示例演示如何使用 PATTERN 参数通过模式匹配从 Amazon S3 加载 CSV 文件,仅加载文件名包含 'sales' 且扩展名为 '.csv' 的文件:
-- 为基于模式的文件加载创建连接
CREATE CONNECTION pattern_s3_conn
STORAGE_TYPE = 's3'
ACCESS_KEY_ID = '<your-access-key-ID>'
SECRET_ACCESS_KEY = '<your-secret-access-key>';
-- 使用模式匹配加载文件名含 'sales' 的 CSV 文件
COPY INTO mytable
FROM 's3://mybucket/'
CONNECTION = (CONNECTION_NAME = 'pattern_s3_conn')
PATTERN = '.*sales.*[.]csv'
FILE_FORMAT = (
TYPE = CSV,
FIELD_DELIMITER = ',',
RECORD_DELIMITER = '\n',
SKIP_HEADER = 1
);
其中 .* 表示任意字符出现零次或多次,方括号用于转义文件扩展名前的点字符 .。
使用连接加载所有 CSV 文件:
COPY INTO mytable
FROM 's3://mybucket/'
CONNECTION = (CONNECTION_NAME = 'pattern_s3_conn')
PATTERN = '.*[.]csv'
FILE_FORMAT = (
TYPE = CSV,
FIELD_DELIMITER = ',',
RECORD_DELIMITER = '\n',
SKIP_HEADER = 1
);
为包含多级目录的 Stage 文件路径指定模式时,请注意模式只匹配 @<stage_name>[/<path>] 之后的路径部分。例如,对于 FROM @sales_stage/raw/,文件 @sales_stage/raw/year=2025/month=01/sales_20250101.parquet 会作为 year=2025/month=01/sales_20250101.parquet 进行匹配。
- 若要匹配前缀后的特定子路径,请在模式中包含该前缀(如 'year=2025/month=01/'),再指定子路径内的匹配模式(如 'sales_')。
-- 文件路径:raw/year=2025/month=01/sales_20250101.parquet
COPY INTO ... FROM @sales_stage/raw/ PATTERN = 'year=2025/month=01/.*sales_.*[.]parquet') ...
- 若要匹配文件路径中任意位置出现的目标模式,请在模式前后加 '.*'(如 '.sales_20250101.')以匹配路径中任意位置的 'sales_20250101'。
-- 文件路径:raw/year=2025/month=01/sales_20250101.parquet
COPY INTO ... FROM @sales_stage/raw/ PATTERN = '.*sales_20250101.*') ...
示例 5:加载到含额外列的表
本节使用示例文件 books.csv 演示如何向含额外列的表加载数据:
Transaction Processing,Jim Gray,1992
Readings in Database Systems,Michael Stonebraker,2004
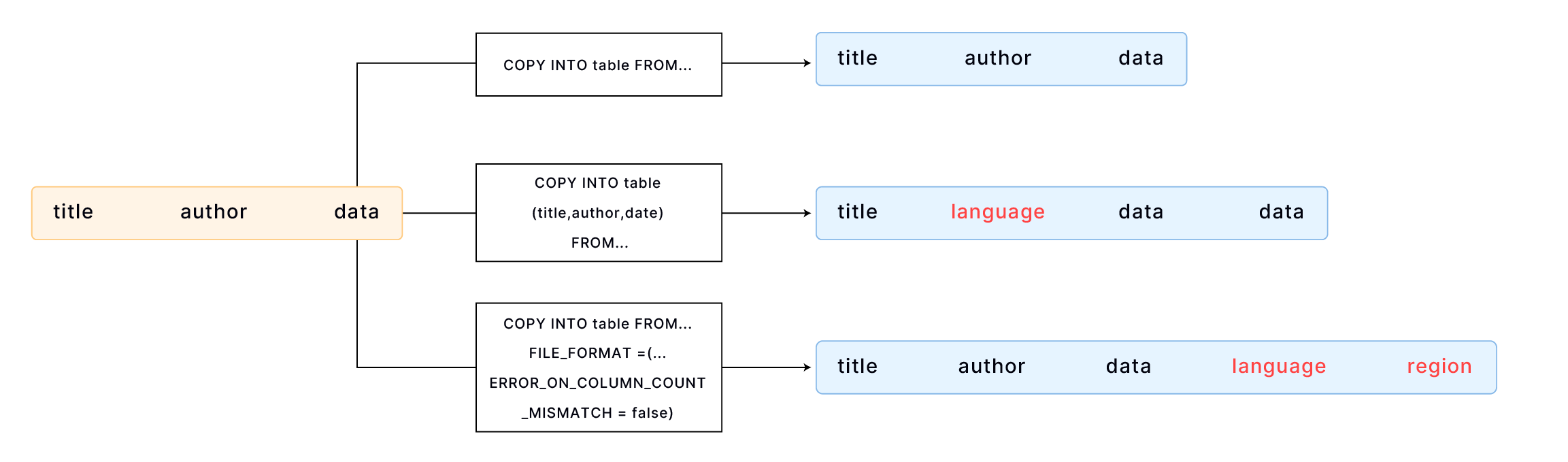
默认情况下,COPY INTO 按文件字段顺序与表列顺序一一对应加载数据,需确保文件与表的数据对齐。例如:
CREATE TABLE books
(
title VARCHAR,
author VARCHAR,
date VARCHAR
);
COPY INTO books
FROM 'https://datafuse-1253727613.cos.ap-hongkong.myqcloud.com/data/books.csv'
FILE_FORMAT = (TYPE = CSV);
若表列多于文件字段,可显式指定加载列:
CREATE TABLE books_with_language
(
title VARCHAR,
language VARCHAR,
author VARCHAR,
date VARCHAR
);
COPY INTO books_with_language (title, author, date)
FROM 'https://datafuse-1253727613.cos.ap-hongkong.myqcloud.com/data/books.csv'
FILE_FORMAT = (TYPE = CSV);
若表列多于文件字段且额外列位于表末尾,可使用 FILE_FORMAT 选项 ERROR_ON_COLUMN_COUNT_MISMATCH 加载数据,无需逐列指定。目前该选项仅支持 CSV 格式。
CREATE TABLE books_with_extra_columns
(
title VARCHAR,
author VARCHAR,
date VARCHAR,
language VARCHAR,
region VARCHAR
);
COPY INTO books_with_extra_columns
FROM 'https://datafuse-1253727613.cos.ap-hongkong.myqcloud.com/data/books.csv'
FILE_FORMAT = (TYPE = CSV, ERROR_ON_COLUMN_COUNT_MISMATCH = false);
表中的额外列可通过 CREATE TABLE 或 ALTER TABLE 指定默认值。若未显式设置,则使用该数据类型的默认值。例如,整型列默认值为 0。
示例 6:使用自定义格式加载 JSON
本示例从 CSV 文件 "data.csv" 加载数据,内容如下:
1,"U00010","{\"carPriceList\":[{\"carTypeId":10,\"distance":5860},{\"carTypeId":11,\"distance\":5861}]}"
2,"U00011","{\"carPriceList\":[{\"carTypeId":12,\"distance":5862},{\"carTypeId":13,\"distance\":5863}]}"
每行三列,第三列为含 JSON 数据的字符串。为正确加载含 JSON 字段的 CSV,需设置合适的转义字符。本例使用反斜杠 \ 作为转义字符,因 JSON 内含双引号 "。
步骤 1:创建自定义文件格式
-- 定义自定义 CSV 文件格式,转义字符设为反斜杠 \
CREATE FILE FORMAT my_csv_format
TYPE = CSV
ESCAPE = '\\';
步骤 2:创建目标表
CREATE TABLE t
(
id INT,
seq VARCHAR,
p_detail VARCHAR
);
步骤 3:使用自定义文件格式加载
COPY INTO t FROM @t_stage FILES=('data.csv')
FILE_FORMAT=(FORMAT_NAME='my_csv_format');
示例 7:加载无效 JSON
向 Variant 列加载数据时,Databend 会自动校验数据有效性,遇到无效数据将报错。例如,用户 Stage 中的 Parquet 文件 invalid_json_string.parquet 含无效 JSON:
SELECT *
FROM @~/invalid_json_string.parquet;
┌────────────────────────────────────┐
│ a │ b │
├─────────────────┼──────────────────┤
│ 5 │ {"k":"v"} │
│ 6 │ [1, │
└────────────────────────────────────┘
DESC t2;
┌──────────────────────────────────────────────┐
│ Field │ Type │ Null │ Default │ Extra │
├────────┼─────────┼────────┼─────────┼────────┤
│ a │ VARCHAR │ YES │ NULL │ │
│ b │ VARIANT │ YES │ NULL │ │
└──────────────────────────────────────────────┘
尝试加载将报错:
COPY INTO t2 FROM @~/invalid_json_string.parquet FILE_FORMAT = (TYPE = PARQUET) ON_ERROR = CONTINUE;
error: APIError: ResponseError with 1006: EOF while parsing a value, pos 3 while evaluating function `parse_json('[1,')`
若需跳过 JSON 有效性检查,可在 COPY INTO 语句中设置 DISABLE_VARIANT_CHECK = true:
COPY INTO t2 FROM @~/invalid_json_string.parquet
FILE_FORMAT = (TYPE = PARQUET)
DISABLE_VARIANT_CHECK = true
ON_ERROR = CONTINUE;
┌───────────────────────────────────────────────────────────────────────────────────────────────┐
│ File │ Rows_loaded │ Errors_seen │ First_error │ First_error_line │
├─────────────────────────────┼─────────────┼─────────────┼──────────────────┼──────────────────┤
│ invalid_json_string.parquet │ 2 │ 0 │ NULL │ NULL │
└───────────────────────────────────────────────────────────────────────────────────────────────┘
SELECT * FROM t2;
-- 无效 JSON 在 Variant 列中以 null 存储
┌──────────────────────────────────────┐
│ a │ b │
├──────────────────┼───────────────────┤
│ 5 │ {"k":"v"} │
│ 6 │ null │
└──────────────────────────────────────┘
示例 8:使用 Schema Evolution 加载
当加载的 Parquet 或 NDJSON 文件结构包含目标表中不存在的列时,可以使用 Schema Evolution 自动添加缺失的列。对于从 Stage 或外部位置加载并触发 Schema Evolution 推断的场景,请确保执行加载的角色拥有目标表的 INSERT 和 ALTER 权限。首先,在表上启用 Schema Evolution:
CREATE OR REPLACE TABLE invoices(order_id INT);
-- 启用 Schema Evolution
ALTER TABLE invoices SET OPTIONS(ENABLE_SCHEMA_EVOLUTION = true);
Parquet
然后加载具有不同结构的 Parquet 文件。Databend 会自动添加新列,缺失的值用 NULL 填充:
-- 假设 @my_stage 中包含带有额外列(如 amount、currency)的 Parquet 文件
COPY INTO invoices
FROM @my_stage/
FILE_FORMAT = (TYPE = PARQUET MISSING_FIELD_AS = FIELD_DEFAULT);
NDJSON
对于 NDJSON,COPY INTO 会使用默认采样值推断缺失列。仅当需要覆盖 Databend 对 staged 文件的采样方式时,才需要添加 SCHEMA_EVOLUTION:
CREATE OR REPLACE TABLE events(id INT);
ALTER TABLE events SET OPTIONS(ENABLE_SCHEMA_EVOLUTION = true);
-- 假设 @events_stage 中包含如下 NDJSON 记录:
-- {"id":1,"city":"SF","score":9}
COPY INTO events
FROM @events_stage/
FILE_FORMAT = (TYPE = NDJSON MISSING_FIELD_AS = FIELD_DEFAULT)
SCHEMA_EVOLUTION = (
SAMPLE_FILES = AUTO,
SAMPLE_RECORDS_PER_FILE = AUTO,
SAMPLE_TOTAL_RECORDS = AUTO
);
Databend 会采样 staged NDJSON 文件,将推断出的 city、score 等字段追加为可空列,然后加载数据。
更多详细信息,请参阅 Schema Evolution。

