OPTIMIZE TABLE
在 Databend 中优化表,即通过合并或清理历史数据来节省存储空间并提升查询性能。
为何需要优化?
Databend 数据存储:快照、段与块
快照(Snapshot)、段(Segment)和块(Block)是 Databend 用于数据存储的核心概念,Databend 利用它们构建表数据的分层存储结构。
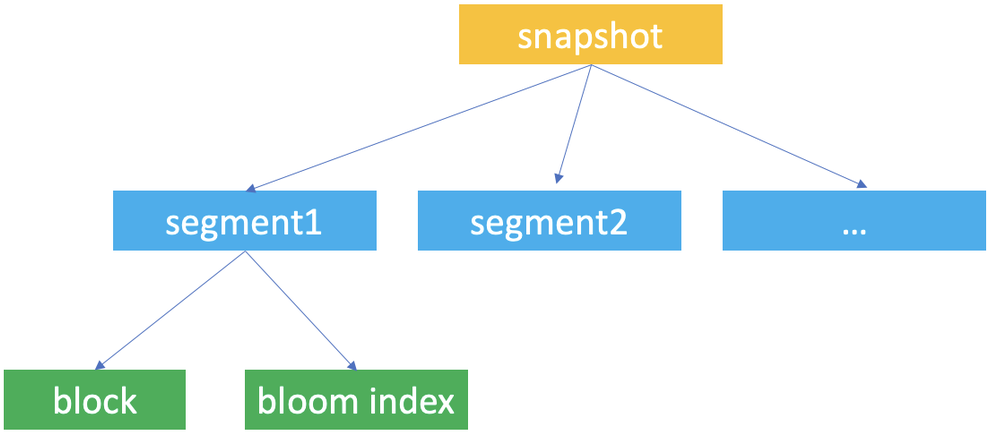
Databend 在数据更新时会自动创建表快照。快照代表表某一版本的段元数据。
使用 Databend 时,若通过 AT 子句检索并查询表的历史版本数据,通常需借助快照 ID 访问快照。
快照是一个 JSON 文件,不存储表数据,但记录了快照关联的段。对表执行 FUSE_SNAPSHOT 可查看保存的快照。
段是一个 JSON 文件,用于组织存储数据的块(至少 1 个,最多 1,000 个)。使用快照 ID 对快照执行 FUSE_SEGMENT 可查看该快照引用的段。
Databend 将实际表数据存储在 Parquet 文件中,并将每个 Parquet 文件视为一个块。使用快照 ID 对快照执行 FUSE_BLOCK 可查看该快照引用的块。
Databend 为每个数据库和表创建唯一 ID,用于存储快照、段和块文件,并将其保存至对象存储路径 <bucket_name>/<tenant_id>/<db_id>/<table_id>/。每个快照、段和块文件均以 UUID(32 位小写十六进制字符串)命名。
| 文件 | 格式 | 文件名 | 存储文件夹 |
|---|---|---|---|
| 快照 | JSON | <32bitUUID>_<version>.json | <bucket_name>/<tenant_id>/<db_id>/<table_id>/_ss/ |
| 段 | JSON | <32bitUUID>_<version>.json | <bucket_name>/<tenant_id>/<db_id>/<table_id>/_sg/ |
| 块 | parquet | <32bitUUID>_<version>.parquet | <bucket_name>/<tenant_id>/<db_id>/<table_id>/_b/ |
表优化
在 Databend 中,建议的理想块大小为 100 MB(未压缩)或 1,000,000 行,每个段包含 1,000 个块。为最大化表优化效果,需明确何时以及如何应用各种优化技术,如段合并和块合并。
-
使用 COPY INTO 或 REPLACE INTO 命令向包含聚簇键(Cluster Key)的表写入数据时,Databend 会自动触发重聚簇以及段和块合并流程。
-
段与块合并支持在集群环境中分布式执行。可通过设置 ENABLE_DISTRIBUTED_COMPACT 为 1 启用,以提升集群环境中的查询性能和可扩展性。
SET enable_distributed_compact = 1;
段合并(Segment Compaction)
当表存在过多小段(每段少于 100 个块)时,需进行段合并。
SELECT
block_count,
segment_count,
IF(
block_count / segment_count < 100,
'该表当前需进行段合并',
'该表当前无需段合并'
) AS advice
FROM
fuse_snapshot('your-database', 'your-table')
LIMIT 1;
语法
OPTIMIZE TABLE [database.]table_name COMPACT SEGMENT [LIMIT <segment_count>]
通过合并小段为较大段来优化表数据。
- LIMIT 选项设置最大合并段数,Databend 将选择并合并最新段。
示例
-- 检查是否需段合并
SELECT
block_count,
segment_count,
IF(
block_count / segment_count < 100,
'该表当前需进行段合并',
'该表当前无需段合并'
) AS advice
FROM
fuse_snapshot('hits', 'hits');
+-------------+---------------+-------------------------------------+
| block_count | segment_count | advice |
+-------------+---------------+-------------------------------------+
| 751 | 32 | The table needs segment compact now |
+-------------+---------------+-------------------------------------+
-- 执行段合并
OPTIMIZE TABLE hits COMPACT SEGMENT;
-- 再次检查
SELECT
block_count,
segment_count,
IF(
block_count / segment_count < 100,
'该表当前需进行段合并',
'该表当前无需段合并'
) AS advice
FROM
fuse_snapshot('hits', 'hits')
LIMIT 1;
+-------------+---------------+---------------------------------------------+
| block_count | segment_count | advice |
+-------------+---------------+---------------------------------------------+
| 751 | 1 | The table does not need segment compact now |
+-------------+---------------+---------------------------------------------+
块合并(Block Compaction)
当表存在大量小块,或插入、删除、更新行比例较高时,需进行块合并。
可通过检查每个块的未压缩大小是否接近理想值 100 MB 来判断。
若大小小于 50 MB,建议执行块合并,表明存在过多小块:
SELECT
block_count,
humanize_size(bytes_uncompressed / block_count) AS per_block_uncompressed_size,
IF(
bytes_uncompressed / block_count / 1024 / 1024 < 50,
'该表当前需进行块合并',
'该表当前无需块合并'
) AS advice
FROM
fuse_snapshot('your-database', 'your-table')
LIMIT 1;
建议先执行段合并,再执行块合并。
语法
OPTIMIZE TABLE [database.]table_name COMPACT [LIMIT <segment_count>]
通过合并小块和段为较大块和段来优化表数据。
-
该命令会为最新表数据创建新快照(含合并后的段和块),不影响现有存储文件,故需清理历史数据后才会释放存储空间。
-
根据表大小,执行可能耗时较长。
-
LIMIT 选项设置最大合并段数,Databend 将选择并合并最新段。
-
合并完成后,Databend 会自动对聚簇表执行重聚簇。
示例
OPTIMIZE TABLE my_database.my_table COMPACT LIMIT 50;

