Cluster Key:自动数据组织加速查询
Cluster Key 提供自动数据组织功能,显著提升大型表的查询性能。Databend 在后台无缝持续管理所有集群操作 - 您只需定义 Cluster Key,Databend 自动处理后续工作。
解决的问题
缺乏合理组织的大型表会引发显著的性能和维护挑战:
| 问题 | 影响 | 自动聚类解决方案 |
|---|---|---|
| 全表扫描 | 查询需扫描全表获取过滤数据 | 自动组织数据,仅读取相关块 |
| 随机数据访问 | 相似数据分散存储 | 持续将相关数据分组存储 |
| 慢速过滤查询 | WHERE 子句扫描无关行 | 自动跳过无关数据块 |
| 高 I/O 成本 | 读取大量未使用数据 | 自动最小化数据传输量 |
| 手动维护 | 需监控并手动重聚类表 | 零维护 - 自动后台优化 |
| 资源管理 | 需为聚类操作分配计算资源 | Databend 自动管理所有聚类资源 |
示例:含数百万产品的电商表。未聚类时,查询 WHERE category IN ('Electronics', 'Computers') 需扫描所有产品类别。通过按类别自动聚类,Databend 持续将电子产品与计算机产品分组存储,仅扫描 2 个数据块而非 1000+ 个块。
自动聚类优势
维护便捷:Databend 无需:
- 监控聚类表状态
- 手动触发重聚类操作
- 分配聚类计算资源
- 安排维护窗口
工作原理:定义 Cluster Key 后,Databend 自动:
- 监控 DML 操作引起的表变更
- 评估表是否需重聚类
- 执行后台聚类优化
- 持续保持最优数据组织
您只需为表定义聚类键(如适用),Databend 将自动管理所有后续维护。
工作原理
Cluster Key 根据指定列将数据组织到存储块(Parquet 文件)中:
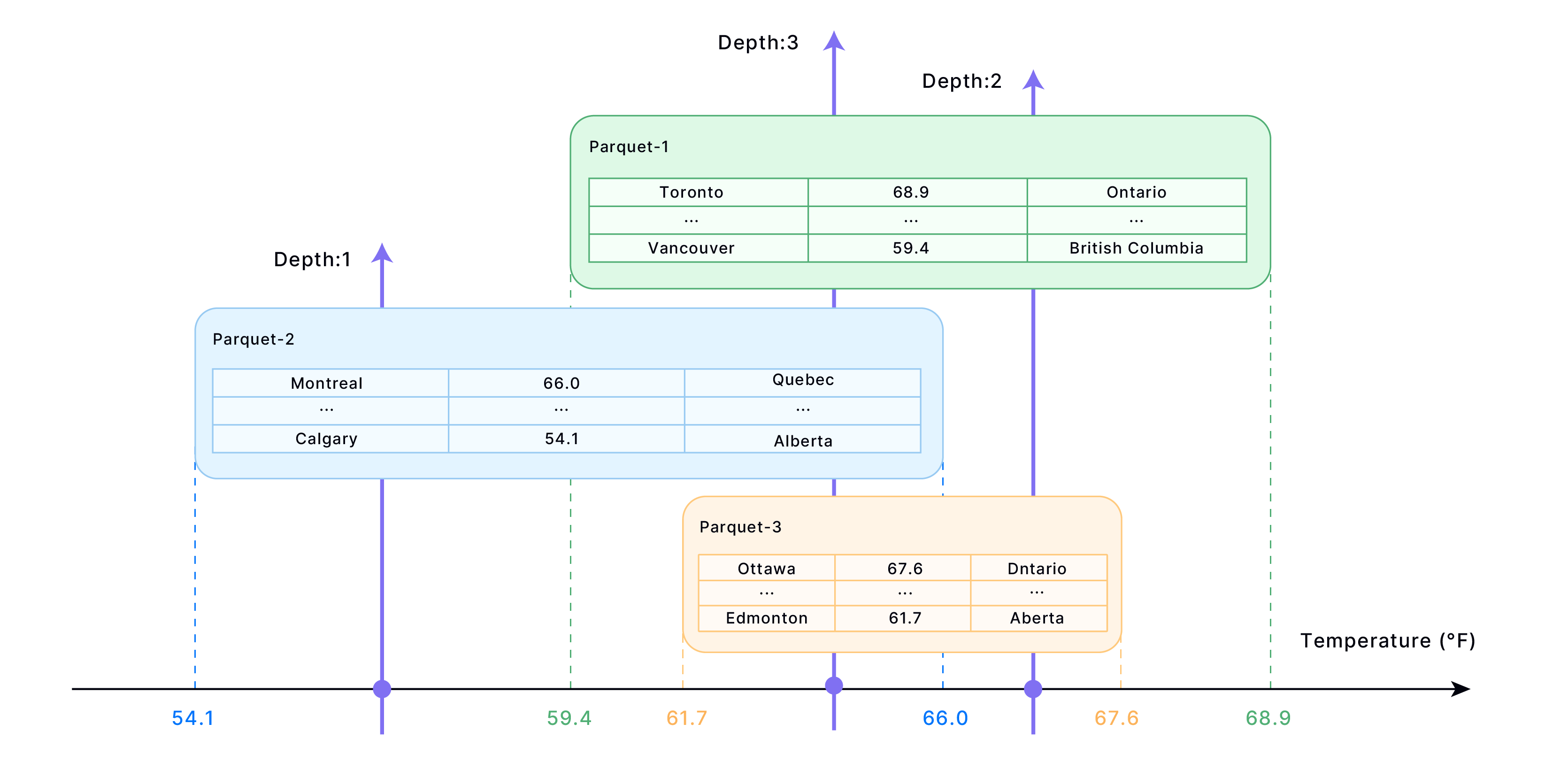
- 数据组织 → 相似值分组至相邻块
- 元数据创建 → 存储块值映射关系实现快速查找
- 查询优化 → 查询时仅读取相关块
- 性能提升 → 减少扫描行数,加速结果返回
快速设置
-- 创建含 cluster key 的表
CREATE TABLE sales (
order_id INT,
order_date TIMESTAMP,
region VARCHAR,
amount DECIMAL
) CLUSTER BY (region);
-- 为现有表添加 cluster key
ALTER TABLE sales CLUSTER BY (region, order_date);
选择合适 Cluster Key
根据常用查询过滤条件选择列:
| 查询模式 | 推荐 Cluster Key | 示例 |
|---|---|---|
| 单列过滤 | 该列 | CLUSTER BY (region) |
| 多列过滤 | 多列组合 | CLUSTER BY (region, category) |
| 日期范围查询 | 日期/时间戳列 | CLUSTER BY (order_date) |
| 高基数列 | 使用表达式降基 | CLUSTER BY (DATE(created_at)) |
优劣 Cluster Key 对比
| ✅ 优选方案 | ❌ 劣选方案 |
|---|---|
| 高频过滤列 | 低频使用列 |
| 中基数(100-10K 值) | 布尔列(取值过少) |
| 日期/时间列 | 唯一 ID 列(取值过多) |
| 区域/类别/状态列 | 随机或哈希列 |
性能监控
-- 检查聚类效果
SELECT * FROM clustering_information('database_name', 'table_name');
-- 关键指标:
-- average_depth: 值越低越好(<2 为优)
-- average_overlaps: 值越低越好
-- block_depth_histogram: 深度 1-2 的块占比越高越好
重聚类时机
数据变更会导致表逐渐失序:
-- 检查是否需重聚类
SELECT IF(average_depth > 2 * LEAST(GREATEST(total_block_count * 0.001, 1), 16),
'Re-cluster needed',
'Clustering is good')
FROM clustering_information('your_database', 'your_table');
-- 重聚类操作
ALTER TABLE your_table RECLUSTER;
性能调优
自定义块大小
调整块大小优化性能:
-- 较小块 = 单次查询处理行数更少
ALTER TABLE sales SET OPTIONS(
ROW_PER_BLOCK = 100000,
BLOCK_SIZE_THRESHOLD = 52428800
);
自动重聚类
COPY INTO和REPLACE INTO自动触发重聚类- 定期监控聚类指标
- 当
average_depth过高时执行重聚类
最佳实践
| 实践方案 | 优势 |
|---|---|
| 从简开始 | 优先使用单列 Cluster Key |
| 监控指标 | 定期检查 clustering_information |
| 性能测试 | 对比聚类前后查询速度 |
| 定期重聚类 | 数据变更后维护聚类状态 |
| 成本考量 | 聚类消耗计算资源 |
重要说明
提示
适用场景:
- 大型表(百万+行)
- 查询性能低下
- 高频过滤查询
- 分析型工作负载
不适用场景:
- 小型表
- 随机访问模式
- 数据变更频繁
Cluster Key 在具有可预测过滤模式的大型高频查询表上效果最佳。建议从最常出现在 WHERE 子句的列开始实施。

