Amazon S3 集成任务
本页介绍如何创建一个 Amazon S3 集成任务,将 S3 存储桶中的文件导入 Databend。当前支持 CSV、Parquet 和 NDJSON 文件格式,并可选择一次性导入或持续导入模式。
如需先创建可复用的 AWS 凭据配置,请参见 Amazon S3 - 访问凭证。
支持的文件格式
| 格式 | 说明 |
|---|---|
| CSV | 以逗号分隔的文本格式,支持自定义分隔符和表头 |
| Parquet | 列式存储格式,适合分析型工作负载 |
| NDJSON | 以换行分隔的 JSON 格式,每行一个 JSON 对象 |
前置条件
- 已创建 Amazon S3 - 访问凭证 数据源
- AWS 凭据对目标 S3 存储桶具备读取权限
- 如果计划启用 Clean Up Original Files,AWS 凭据还需要具备写入和删除权限
创建 S3 集成任务
步骤 1:基本信息
-
前往 Data > Data Integration,点击 Create Task。
-
选择一个 S3 数据源,然后配置基本参数:
| 字段 | 是否必填 | 说明 |
|---|---|---|
| Data Source | 是 | 从下拉列表中选择已有的 Amazon S3 - 访问凭证 数据源 |
| Name | 是 | 当前集成任务名称 |
| File Path | 是 | S3 URI,可包含通配符(例如 s3://mybucket/data/2025-*.csv) |
| File Type | 自动 | 根据文件扩展名自动识别;当前支持 CSV、Parquet、NDJSON |
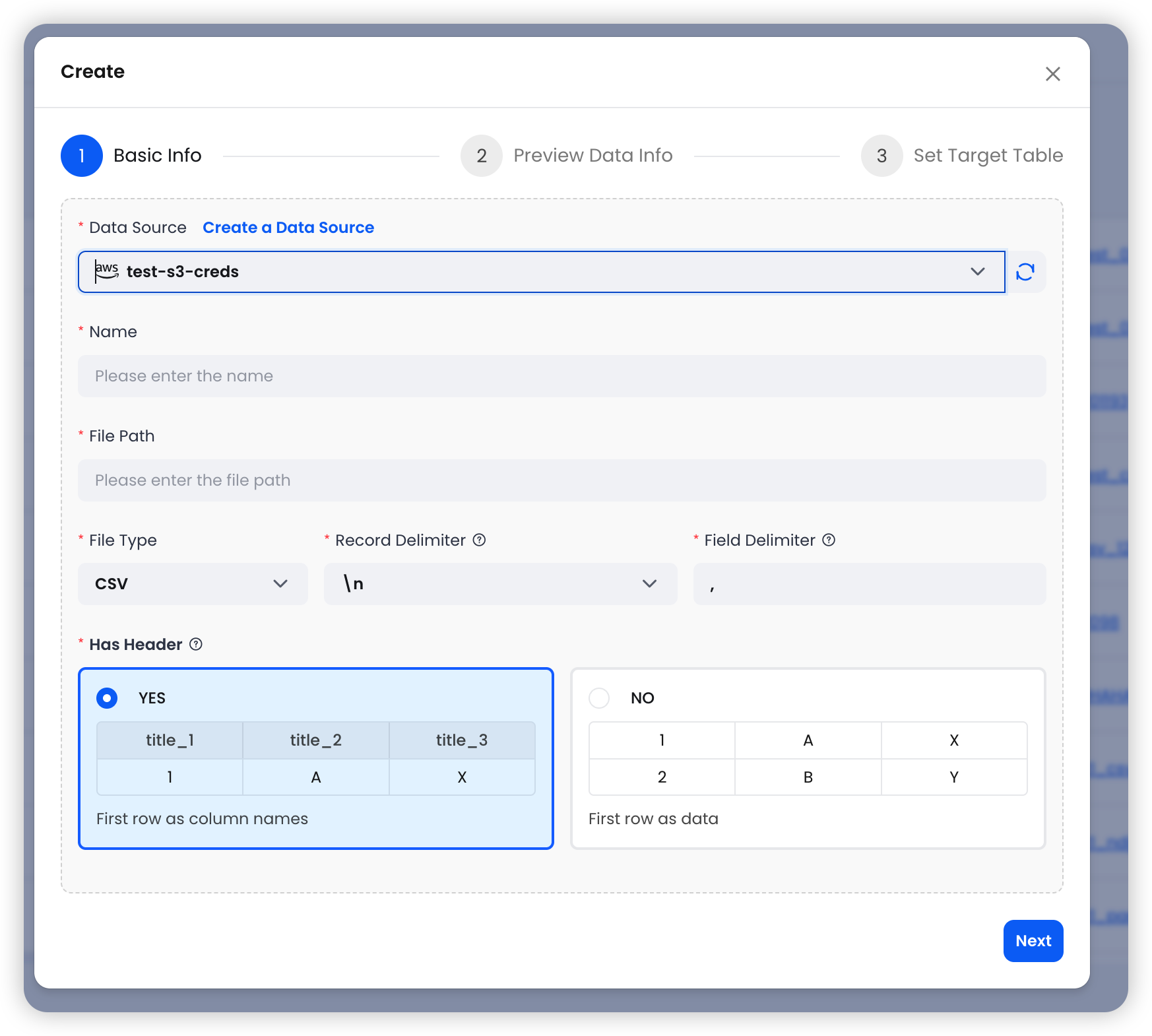
CSV 选项
当文件类型为 CSV 时,可配置以下附加选项:
| 字段 | 默认值 | 说明 |
|---|---|---|
| Record Delimiter | \n | 行分隔符,可选 \n、\r、\r\n |
| Field Delimiter | , | 列分隔符,支持自定义 |
| Has Header | 是 | 首行是否包含列名;关闭后,列会自动命名为 c1、c2、c3 等 |
文件路径模式
File Path 支持使用通配符匹配多个文件:
s3://mybucket/data/2025-*.csv # 匹配所有以 "2025-" 开头的 CSV 文件
s3://mybucket/logs/*.parquet # 匹配日志目录下所有 Parquet 文件
s3://mybucket/events/data.ndjson # 匹配单个指定文件
步骤 2:预览数据
完成基本设置后,点击 Next 预览源数据。
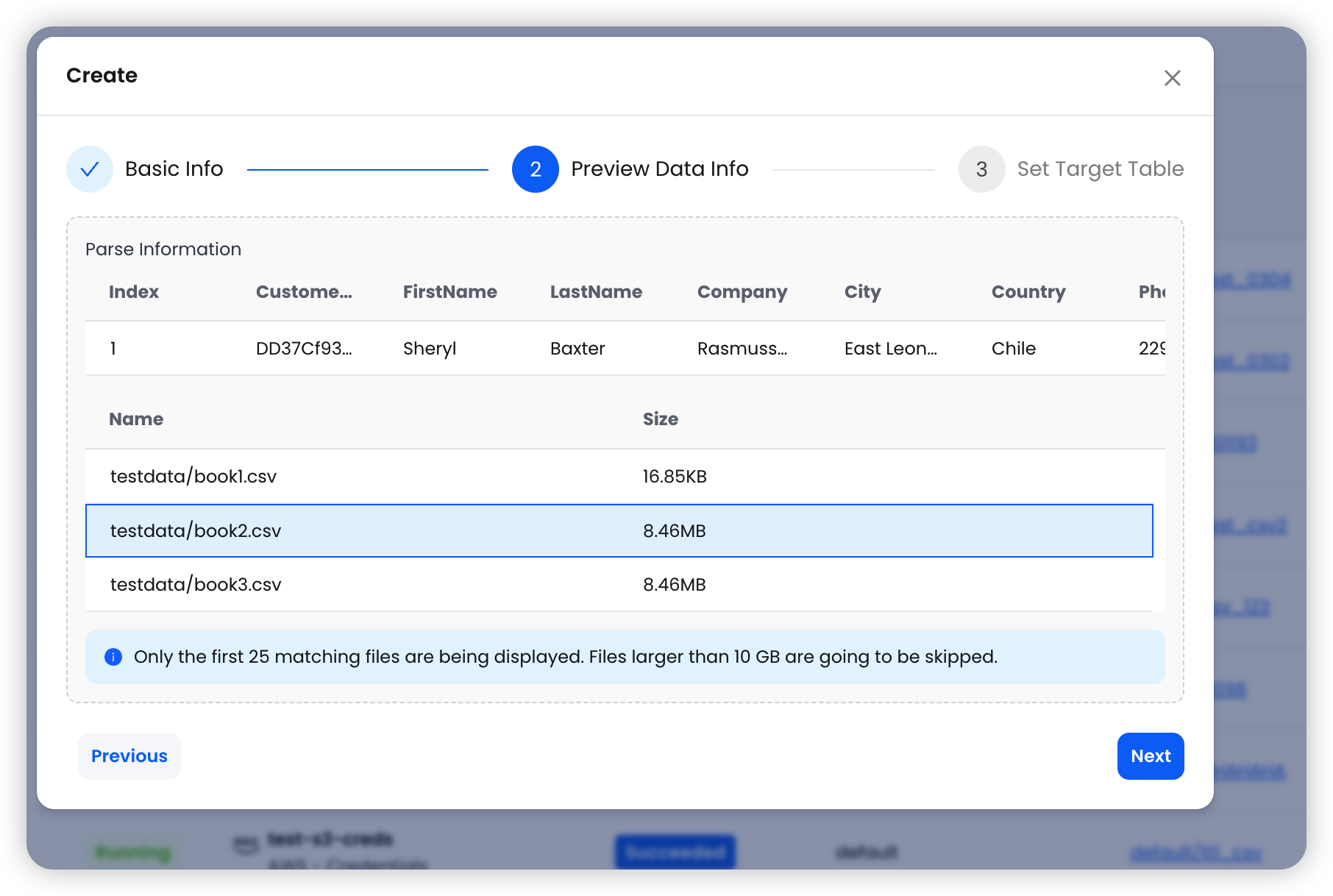
系统会读取第一个匹配到的文件,并显示:
- 包含列名和数据类型的示例数据
- 匹配到的文件列表(最多 25 个)及其大小
备注
预览阶段会跳过大于 10GB 的文件,且最多只显示前 25 个匹配文件。
步骤 3:设置目标表
配置 Databend 中的目标位置:
| 字段 | 说明 |
|---|---|
| Warehouse | 选择用于运行导入任务的 Databend Cloud Warehouse |
| Target Database | 选择 Databend 中的目标数据库 |
| Target Table | Databend 中的目标表名 |
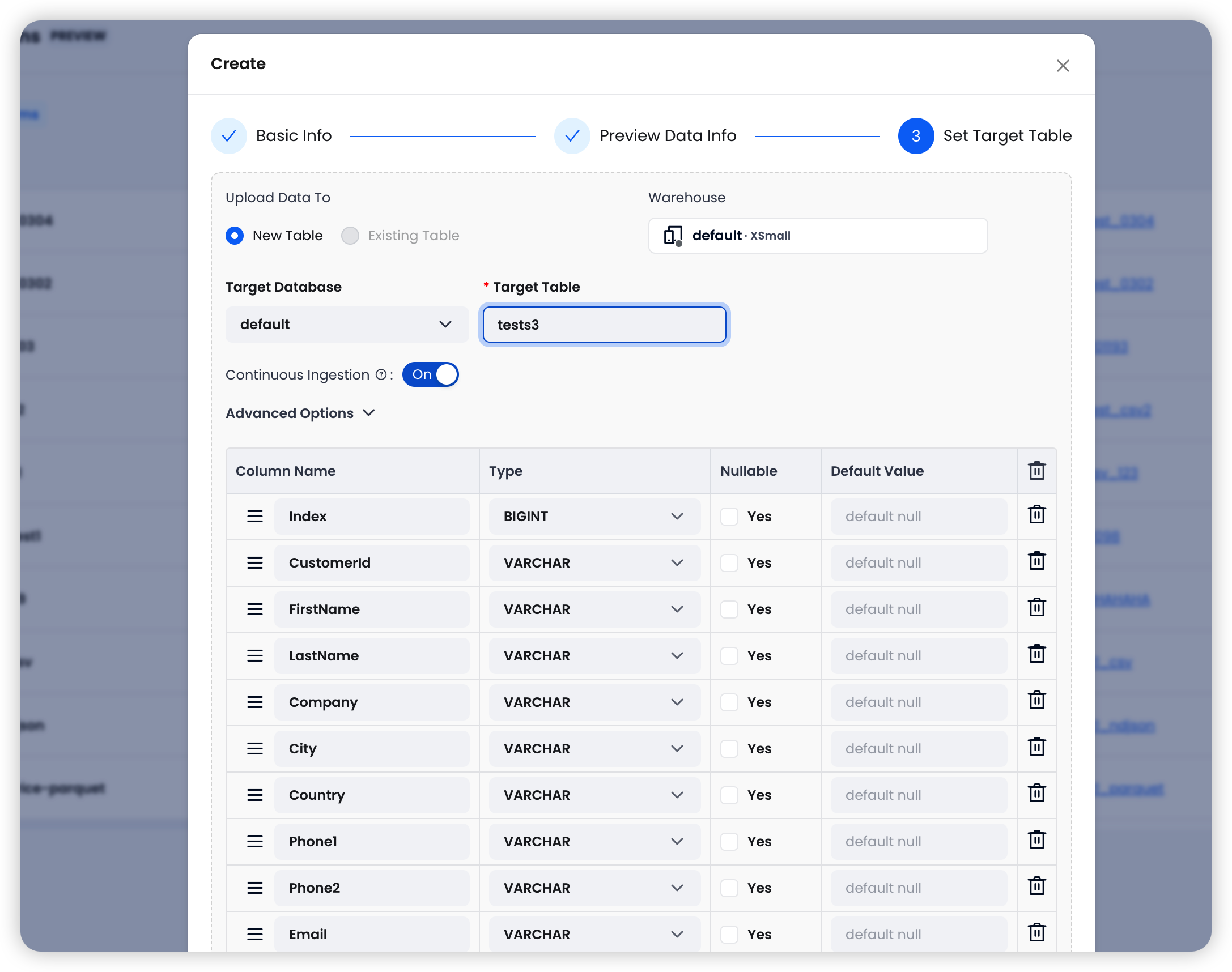
系统会自动从源文件中识别列。继续之前,您可以检查并编辑列名和数据类型。
导入选项
| 选项 | 默认值 | 说明 |
|---|---|---|
| Continuous Ingestion | 开启 | 启用后,系统会周期性(每 30 秒)轮询 S3 路径并导入新文件 |
| Error Handling | Abort | Abort:遇到首个错误即停止;Continue:跳过出错行并继续导入 |
| Clean Up Original Files | 关闭 | 启用后,成功导入后会从 S3 删除源文件 |
| Allow Duplicate Imports | 关闭 | 启用后,允许重新导入已导入过的文件 |
提示
如果 S3 路径下会持续产生新文件,并希望它们自动导入 Databend,请启用 Continuous Ingestion。如果只是一次性导入,请关闭该选项。
点击 Create 完成集成任务创建。
任务行为
| Continuous Ingestion | 行为 |
|---|---|
| On | 持续运行,每 30 秒轮询一次 S3 以检查新文件,并自动导入。 |
| Off | 仅对匹配文件执行一次导入后即停止。除非启用 Allow Duplicate Imports,否则已导入的文件会被跳过。 |
高级配置
Continuous Ingestion
启用后,任务会以长期运行进程的形式定期扫描 S3 路径中的新文件。每个周期会执行:
- 列出匹配文件路径模式的对象
- 识别尚未导入的新文件
- 使用
COPY INTO将新文件导入目标表 - 在任务历史中记录导入结果
这适用于上游系统持续向 S3 写入新文件的数据管道场景。
Error Handling
- Abort(默认):导入在遇到第一个错误时立即停止。适用于对数据质量要求严格、希望先排查问题再继续的场景。
- Continue:跳过导致错误的行,并继续导入其余数据。适用于允许部分导入、希望尽可能提高吞吐的场景。
Clean Up Original Files (PURGE)
启用后,源文件在成功导入 Databend 后会从 S3 中删除。这有助于控制存储成本并避免重复处理。请确保您的 AWS 凭据在目标存储桶上具备 s3:DeleteObject 权限。
Allow Duplicate Imports (FORCE)
默认情况下,系统会跟踪哪些文件已经导入,并在后续运行中跳过它们。启用该选项后,无论文件之前是否已导入,系统都会重新导入所有匹配文件。这适用于表结构变更或数据修正后需要重新加载数据的场景。

