Iceberg Catalog
- RFC PR: datafuselabs/databend#8215
- Tracking Issue: datafuselabs/databend#8216
Summary
Iceberg 是一种在数据湖仓中被广泛支持的表格式。 本 RFC 描述了 iceberg 外部 catalog 的行为方式以及我们将如何实现它。
Motivation
Apache Iceberg 是一种在数据湖仓中广泛使用的表格式,它提供了更完整的数据库逻辑视图,并且在作为外部表访问时具有更高的性能,因为与 Hive 相比,用户不需要了解分区,并且在访问时减少了通过文件的索引。
Iceberg 的拆分和良好定义的结构也使得对数据源的并发访问和版本管理更加安全、节省和方便。
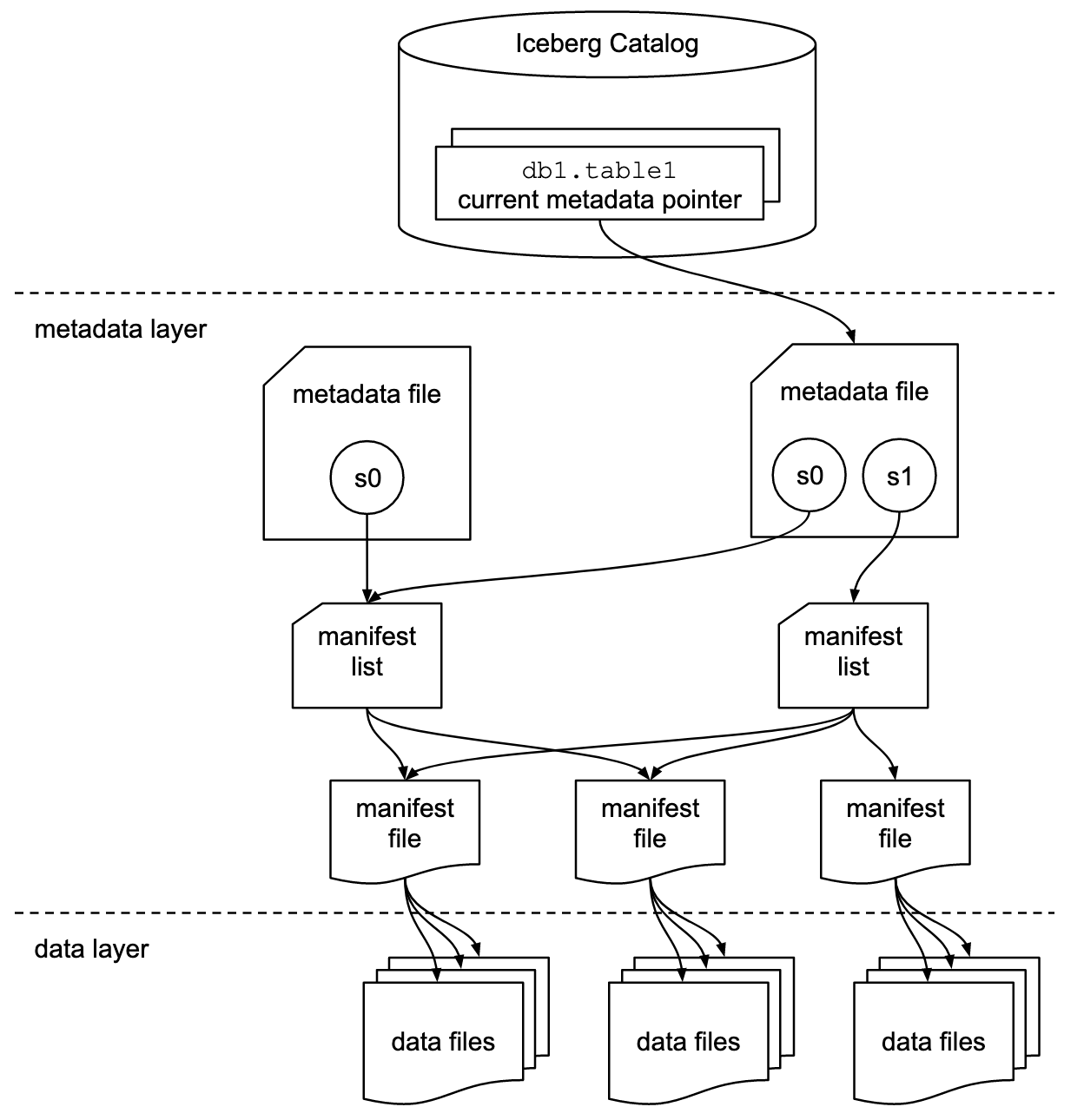
支持 Iceberg 将使 Databend 成为一个开放的数据湖,赋予其更多的 OLAP 能力。
Guide-level explanation
Create Iceberg Catalog
要使用 Iceberg catalog,用户需要建立一个具有必要权限的 iceberg 存储。然后他们可以在其上创建一个 catalog。
CREATE CATALOG my_iceberg
TYPE="iceberg"
URL='s3://path/to/iceberg'
CONNECTION=(
ACCESS_KEY_ID=...
SECRET_ACCESS_KEY=...
...
)
Accessing Iceberg Table's content
SELECT * FROM my_iceberg.iceberg_db.iceberg_tbl;
对普通表和 Iceberg 表进行联合查询:
SELECT normal_tbl.book_name,
my_iceberg.iceberg_db.iceberg_tbl.author
FROM normal_tbl,
iceberg_tbl
WHERE normal_tbl.isbn = my_iceberg.iceberg_db.iceberg_tbl.isbn
AND iceberg_tbl.sales > 100000;
在操作表时,所有数据仍然保留在用户提供的终端上。
Time Travel
Iceberg 提供了一个快照列表及其时间戳。在其上进行时间回溯是很自然的。
SELECT ...
FROM <iceberg_catalog>.<database_name>.<table_name>
AT ( { SNAPSHOT => <snapshot_id> | TIMESTAMP => <timestamp> } );
Accessing Snapshot Metadata
用户应该能够查找 catalog 中的快照 ID 列表:
SELECT snapshot_id FROM ICEBERG_SNAPSHOT(my_iceberg.iceberg_db.iceberg_tbl);
snapshot_id
---------------------
1234567890123456789
1234567890123456790
(2 rows)
外部表当前正在读取的快照 ID 将始终是最新的。但是用户可以使用带有 AT 的 time travel。
Reference-level explanation
一种新的 catalog 类型 ICEBERG,以及用于从 Iceberg 存储读取数据的表引擎。
Table Engine
表引擎使用户能够从已建立的 Apache Iceberg 端点读取数据。外部表的所有表内容和元数据应以 Iceberg 的方式保留在用户提供的 Iceberg 数据源中。
该引擎将跟踪上次提交的快照,并且应该能够从以前的快照中读取。
external-location
无论 Iceberg 在哪里,例如 S3、GCS 或 OSS,如果 Databend 支持该存储,则应该可以访问 Iceberg。用户需要告诉 databend Iceberg 存储在哪里,以及 databend 应该如何访问该存储。
Type convention
| Iceberg | Note | Databend |
|---|---|---|
boolean | True or false | BOOLEAN |
int | 32 bit signed integer | INT32 |
long | 64 bit signed integer | INT64 |
float | 32 bit IEEE 754 float point number | FLOAT |
double | 64 bit IEEE 754 float point number | DOUBLE |
decimal(P, S) | Fixed point decimal; precision P, scale S | not supported |
date | Calendar date without timezone or time | DATE |
time | Timestamp without date, timezone | TIMESTAMP, convert date to today |
timestamp | Timestamp without timezone | TIMESTAMP, convert timezone to GMT |
timestamptz | Timestamp with timezone | TIMESTAMP |
string | UTF-8 string | VARCHAR |
uuid | 16-byte fixed byte array, universally unique identifiers | VARCHAR |
fixed(L) | Fixed-length byte array of length L | VARCHAR |
binary | Arbitrary-length byte array | VARCHAR |
struct | a tuple of typed values | OBJECT |
list | a collection of values with some element type | ARRAY |
map | OBJECT |
Drawbacks
None
Rationale and alternatives
Iceberg External Table
从 Iceberg 存储创建一个外部表:
CREATE EXTERNAL TABLE [IF NOT EXISTS] [db.]table_name
[(
<column_name> <data_type> [ NOT NULL | NULL] [ { DEFAULT <expr> }],
<column_name> <data_type> [ NOT NULL | NULL] [ { DEFAULT <expr> }],
...
)] ENGINE=ICEBERG
ENGINE_OPTIONS=(
DATABASE='db0'
TABLE='tbl0'
LOCATION=<external-location>
)
将引入一个新的表引擎 ICEBERG,所有数据将仍然保留在 Iceberg 存储中。外部表还应该支持用户查询其快照数据和时间回溯。
SELECT snapshot_id FROM ICEBERG_SNAPSHOT('<db_name>', '<external_table_name');
snapshot_id
--------------
73556087355608
经过讨论,选择了上面的 catalog 方式,因为它对 Iceberg 功能的更完整支持,并且更符合当前 Hive catalog 的设计。
Prior art
None
Unresolved questions
None
Future possibilities
Create Table from Iceberg Snapshots
Iceberg 提供快照功能,可以从中创建表。
CREATE TABLE [IF NOT EXISTS] [db.]table_name
(
<column_name> <data_type> [ NOT NULL | NULL] [ { DEFAULT <expr> }],
<column_name> <data_type> [ NOT NULL | NULL] [ { DEFAULT <expr> }],
...
) ENGINE = `ICEBERG`
ENGINE_OPTIONS = (
URL = 's3://path/to/iceberg'
DATABASE = <iceberg_db>
TABLE = <iceberg_tbl>
[ SNAPSHOT = { SNAPSHOT_ID => <snapshot_id> | TIMESTAMP => <timestamp> } ]
)
Schema Evolution
外部表中使用的默认 Iceberg 快照应始终是最新提交的快照:
SELECT snapshot_id from ICEBERG_SNAPSHOT(iceberg_catalog.iceberg_db.iceberg_tbl);
snapshot_id
---------------
0000000000001
支持模式演化使 databend 能够修改 Iceberg 的内容。 例如,将新记录插入到 Iceberg 表中:
INSERT INTO iceberg_catalog.iceberg_db.iceberg_tbl VALUES ('datafuselabs', 'How To Be a Healthy DBA', '2022-10-14');
这将在 Iceberg 存储中创建一个新快照:
SELECT snapshot_id from ICEBERG_SNAPSHOT(iceberg_catalog.iceberg_db.iceberg_tbl);
snapshot_id
---------------
0000000000001
0000000000002

